

vLLM团队推出首个覆盖全模态的推理框架vLLM-Omni,把文本、图片、语音、视频的统一生成从“实验演示”落地为可直接使用的代码。项目已在GitHub和ReadTheDocs上线,开发者现在即可通过pip安装并调用。
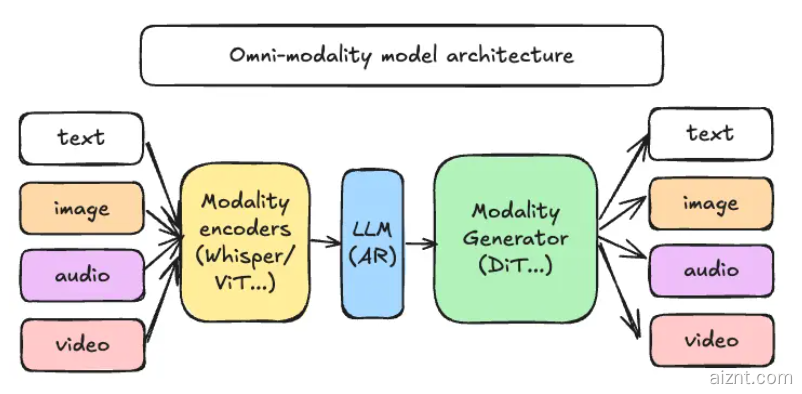
解耦的流水线设计
– 模态编码器:如ViT、Whisper,将图像与音频转换为中间特征
– LLM核心:沿用vLLM自回归引擎,负责推理、规划与对话
– 模态生成器:采用DiT、Stable Diffusion等扩散模型解码输出,可同步生成图像、音频、视频

框架将这三部分设计为独立微服务,可在不同GPU或节点间灵活调度,资源按需扩缩——图像生成高峰期横向扩容DiT,文本推理低谷时缩减LLM,整体显存利用率可提升最高40%。
性能与兼容性
vLLM-Omni内置Python装饰器@omni_pipeline,用三行代码就能把现有单模态模型拼成多模态应用。官方基准显示:在8×A100集群上运行10亿参数的“文本+图像”模型,吞吐量较传统串行方案提升2.1倍,端到端延迟降低35%。

开源与路线图
GitHub仓库已提供完整示例与Docker Compose脚本,兼容PyTorch 2.4+与CUDA 12.2。团队表示,2026年第一季度将加入视频DiT与语音Codec模型,并计划提供Kubernetes CRD,方便企业在私有云一键部署。
行业观点
行业观察者认为,vLLM-Omni把异构模型统一到同一数据流,能降低多模态应用的落地门槛,但跨硬件的负载均衡与缓存一致性在生产环境仍是难题。随着框架不断完善,AI初创团队可以更低成本搭建“文本-图像-视频”一体化平台,而不必各自维护三条推理链路。
项目地址:https://github.com/vllm-project/vllm-omni

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?