

大模型赛道再添重磅进展。国产 AI 厂商 DeepSeek 今日官宣推出新一代旗舰模型 DeepSeek V4。本次更新的核心看点在于更清晰的产品分层:通过 Flash 与 Pro 两个版本,既覆盖高频、轻量的日常应用,又面向复杂推理场景,且以极具竞争力的价格体系,再次推动 AI 商业化定价向更友好方向演进。
模型矩阵:Flash 与 Pro 的差异化定位
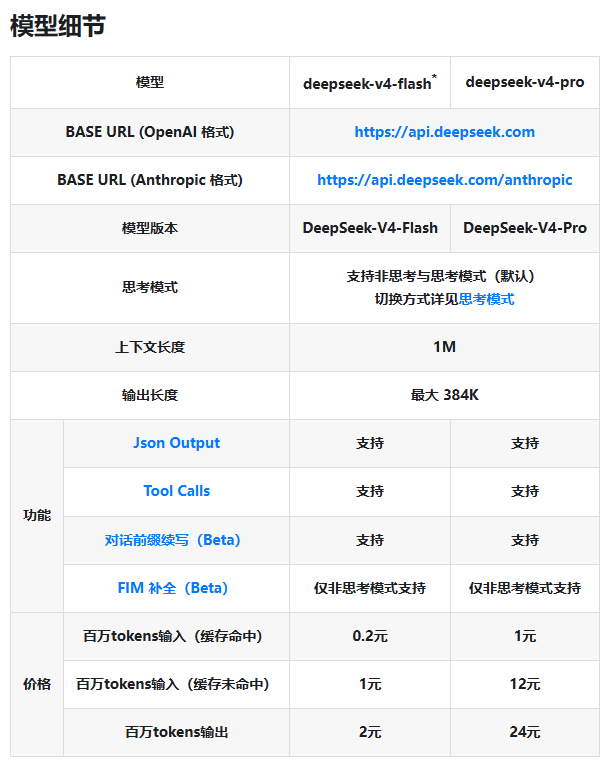
DeepSeek V4 在整合并升级原有 deepseek-chat 与 deepseek-reasoner 的基础上,正式形成两条产品线:
-
DeepSeek‑V4‑Flash:主打高性价比与大吞吐,适配需要快速响应的通用对话与基础文本处理。
-
DeepSeek‑V4‑Pro:面向复杂逻辑、深入推理与高性能算力场景优化,具备更强的思考与处理能力。
两款模型均支持思考模式(特定场景除外)、JSON 输出、Tool Calls,以及对话前缀续写(Beta);同时提供最高 1M 上下文窗口与至多 384K 的输出长度,为复杂工程化落地提供有力支撑。

价格体系:高度透明,阶梯式计费
此次 DeepSeek 公布了清晰的计费逻辑,并通过缓存机制大幅降低长期调用的边际成本。以下为各模型的具体计费标准(单位:元/百万 Tokens):
| 模型名称 | 输入(缓存命中) | 输入(缓存未命中) | 输出 |
| DeepSeek‑V4‑Flash | 0.2元 | 1元 | 2元 |
| DeepSeek‑V4‑Pro | 1元 | 12元 | 24元 |
说明:系统将优先消耗赠送余额,随后再从充值余额中扣减。
行业观察:这一定价为何具备里程碑意义?
从整体策略看,DeepSeek 通过区分“缓存命中”与“未命中”的费用,鼓励开发者进行缓存优化,以降低重复调用开销,从而实现更细粒度的成本控制。
对开发者来说,Flash 版本在缓存未命中的情况下,输入仅 1 元/百万 Token,显著降低接入高水准 MoE 架构的门槛;而 Pro 版本的定价则为知识库问答、自动化代理(Agent)等高复杂度场景提供了兼顾性能与成本的国产选择。
关于兼容性的特别提醒
官方提示:原有的 deepseek-chat 与 deepseek-reasoner 模型名称后续将被正式弃用。为保证业务平滑迁移,开发者现可直接调用 deepseek-v4-flash(对应非思考模式)与 deepseek-v4-pro(对应思考模式)。
更多接口细节与迁移说明,请访问

















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?