

阿里通义实验室的 Qwen Pilot 团队近日提出全新算法 FIPO(Future-KL Influenced Policy Optimization),专门用来突破大模型在推理流程中的瓶颈。以往的强化学习方法(RLVR)在处理推理链的每个 Token 时,难以判断哪些词对最终答案最关键,因此“如何精确找出关键 Token”成了必须解决的问题。

FIPO 引入了 Future-KL 机制,重点奖励对后续推理影响显著的 Token,从根源上缓解了纯 RL 训练常见的“推理长度停滞”现象。实测中,在 32B 规模且仅用 RL 的设置下,FIPO 的表现超过了同量级的 o1-mini 和 DeepSeek-Zero-MATH。

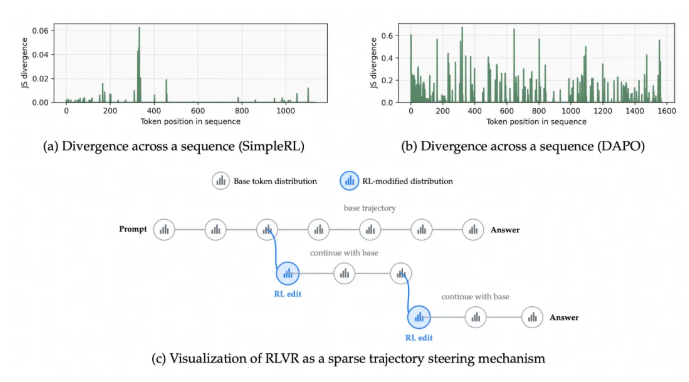
团队研究发现,多数 Token 在训练前后几乎不变,说明强化学习的有效作用非常稀疏。行业常用的评估指标(如熵与 KL 散度)难以精准定位关键 Token 的变化。为此,他们加入了新的观察指标——符号对数概率差(Δlog p),更好地捕捉优化的方向性。
在零基础模型 Qwen2.5-32B-Base 上的测试显示,FIPO 成功打破推理长度上限,平均推理长度提升到 10,000 Token 以上;同时推理准确率也明显提高,展现出在复杂数学推理任务中的强大潜力。
划重点:
🔍 FIPO 由阿里通义实验室推出,目标是提升大模型的推理能力。
📈 它能精准识别对推理至关重要的 Token,推动推理长度突破瓶颈。
🧠 实验表明,FIPO 在复杂数学推理上的成绩显著优于传统方法。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?