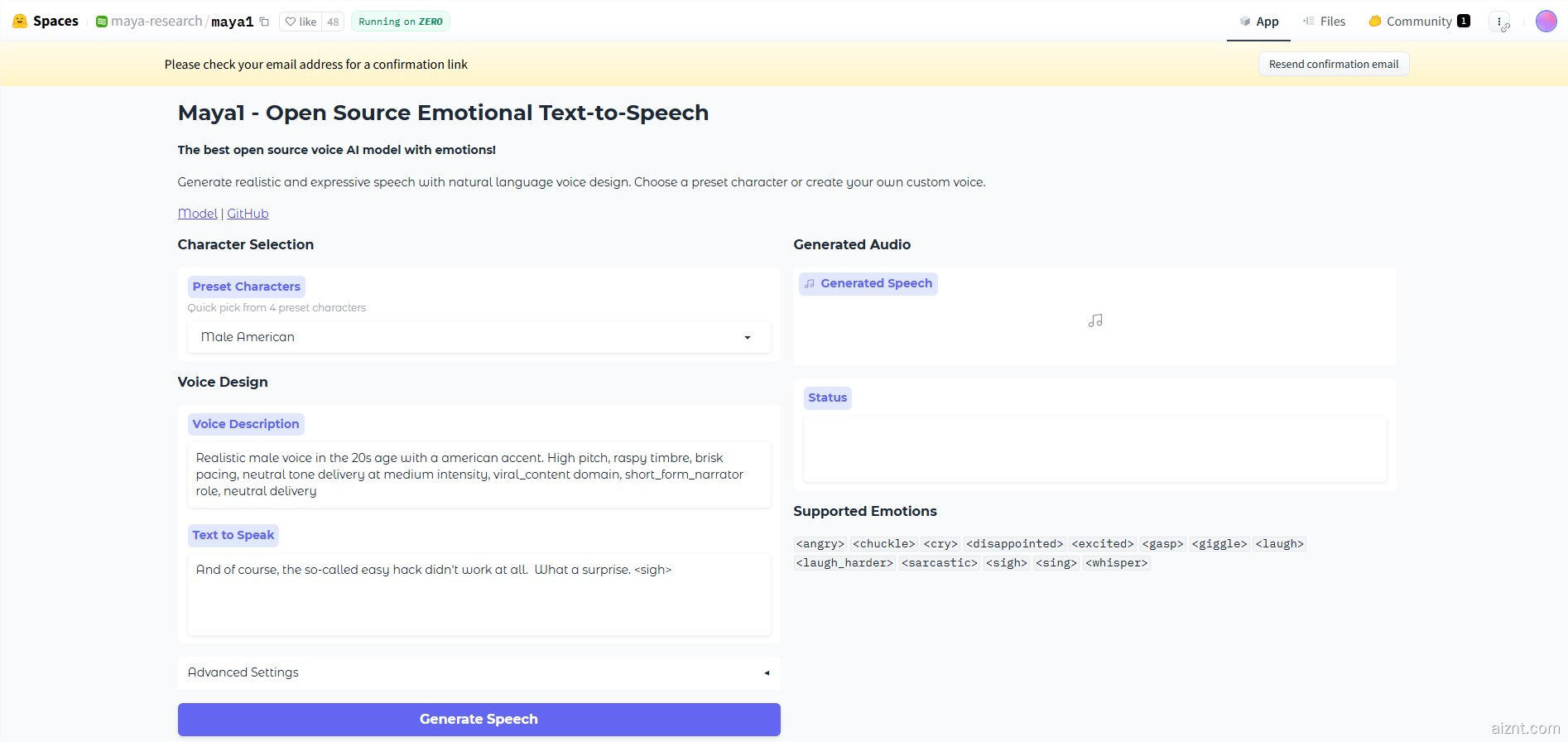


Maya Research 近期推出了 Maya1,这是一款拥有 30 亿参数的文本转语音模型。它能把文字与简短的声音描述转成可控、富有表现力的语音,并可在单张 GPU 上进行实时生成。Maya1 的关键优势在于对真实人类情绪的捕捉以及精准的声音塑造。

Maya1 的使用方式包含两个输入:用自然语言描述你想要的声音,以及需要朗读的文本。例如,可以输入“二十多岁女性,英式口音,活力十足,发音清晰”,或“恶魔角色,男声,低沉,沙哑,慢速”。模型会综合文本内容与风格描述,生成与之匹配的音频。你还可以在文本里插入情感标记,如 < 笑 >、< 叹气 >、< 低语 > 等,内置超过 20 种情感可选。
Maya1 输出为 24kHz 单声道音频,并支持实时流式播放,适用于助手、互动代理、游戏、播客和直播等场景。Maya Research 团队表示,模型表现优于不少顶级的闭源系统,同时完全开源,遵循 Apache 2.0 许可证。
在技术架构上,Maya1 采用仅解码器的 Transformer,设计与 Llama 相近。它不直接生成原始波形,而是预测名为 SNAC 的神经音频编码器的码流。完整的生成流程包括文本解析、编码生成与音频解码,既提高效率,又便于扩展。
数据层面,Maya1 先在互联网规模的英文语音语料上训练,覆盖广泛的声学特征与自然连贯性;随后在精心挑选的私有数据集上进行微调,该数据含有人为审核的声音描述与丰富的情感标签。
为在单卡上推理与部署,官方建议使用显存 16GB 及以上的 GPU,如 A100、H100 或 RTX 4090。Maya Research 也提供多种工具与脚本,便于实时音频生成与流式传输。
huggingface:https://huggingface.co/spaces/maya-research/maya1
划重点:
🎤 30 亿参数的开源 TTS 模型 Maya1,支持实时生成且表现力强。
💡 结合声音描述与朗读文本,支持多种情感标签,语音更生动。
🚀 单个 GPU 即可运行,并配套工具与脚本,助力高效推理和部署。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?