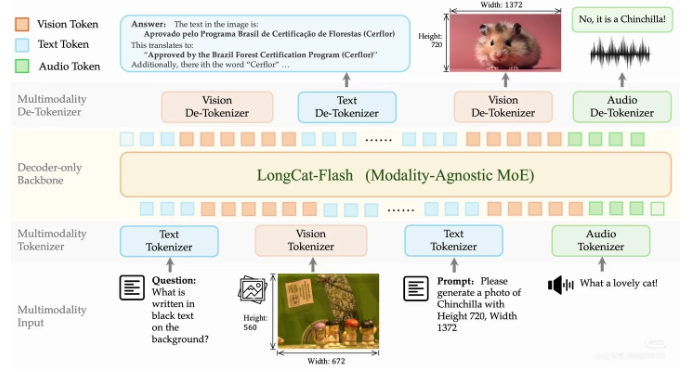


全球人工智能领域正迎来一轮围绕“AI母语”的技术升级。针对当下许多大模型普遍采用“以语言为主、再外挂视觉或语音模块”的拼接式异构架构,相关研发团队近日正式推出并开源了全新的原生多模态大模型 LongCat-Next,以及其核心离散分词器,目标是打通不同模态之间的壁垒,让 AI 像理解文字一样,自然地感知和理解物理世界。
这次突破的关键,在于对 AI 底层架构进行了重新设计。团队在研究中发现,在统一的建模框架和优化目标下,能够建立一种语义完整的离散表示体系。基于这一点,LongCat-Next 采用了全新的 DiNA(离散原生自回归)架构,彻底改写了以往多模态信息只能“被投影”、却难以“被内化”的局面。该架构把图像、声音和文字统一转换为同源的离散 Token,让所有模态在底层模型中共用同一套参数、注意力机制和损失函数。不管是视觉的看与画,还是听觉的听与说,最终都在数学形式上统一为简洁的“下一 Token 预测(NTP)”,从而兼顾了架构简化与部署轻量化。

在“视觉单词”的构建方面,团队首次提出了 dNaViT(离散原生分辨率视觉分词器)技术。这项技术支持原生任意分辨率,在文档解析、复杂图表推理等对细节要求很高的任务中表现突出。dNaViT 采用了 8 层残差向量量化(RVQ)机制,实现了最高 28 倍的高效像素空间压缩,并借助解耦的双轨生成解码器,保证图像和文本还原都具备很高保真度。这样的设计打通了“图像→Token→图像”的完整闭环,让模型能够在语言系统内部真正学习并形成属于自己的视觉语言。
针对业内普遍认为“离散化必然带来信息损失”的问题,团队通过构建 SAE(语义对齐编码器)对表征进行分层拟合,成功在有限的离散空间中逼近高维连续表示,证明离散表示同样可以成为统一理解和生成的完整载体。在以 LongCat-Flash-Lite MoE(68.5B总参数,3B激活参数)为底座的基准测试中,LongCat-Next 展现出很强的工业级跨模态协同能力。在 OmniDocBench 测试里,它的成绩不仅超过了 Qwen3-Omni,还进一步击败了专用视觉模型 Qwen3-VL,打破了外界对离散模型不擅长细粒度感知的固有印象。
另外,这一统一框架在实现跨模态协同能力的同时,也没有牺牲其核心语言能力。数据显示,LongCat-Next 在 MMLU-Pro 和 C-Eval 等纯文本测试中始终保持领先;在工具调用和代码编写方面,其 SWE-Bench 表现也明显优于同类模型。在音频方向,这款模型同样表现抢眼,不仅在 SeedTTS 的中英文语音合成任务中实现了很低的误字率,还支持低延迟的并行文本语音生成以及个性化语音克隆。随着该模型在

















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?