

谷歌 DeepMind 近期发布了一种名为“解耦式 DiLoCo”的分布式训练方案,目标是让大规模人工智能模型的训练更高效,同时在硬件出错时依然稳定可靠。
在传统做法中,计算节点在更新梯度时需要严密同步,一台机器出问题就可能拖慢整体进度。为突破这一瓶颈,解耦式 DiLoCo 将训练拆分到多个异步、相互隔离的“计算岛”,让每个计算单元自行推进训练,而不必等待其他节点。

该架构的关键是把训练任务分配给多个称为“学习单元”的集群。每个学习单元会在本地进行多步梯度更新,再把压缩后的梯度信息发送给外部优化器统一聚合。由于流程是异步的,即便某个单元掉线,其他单元也能继续训练,避免传统方法中的单点故障导致全局停滞。
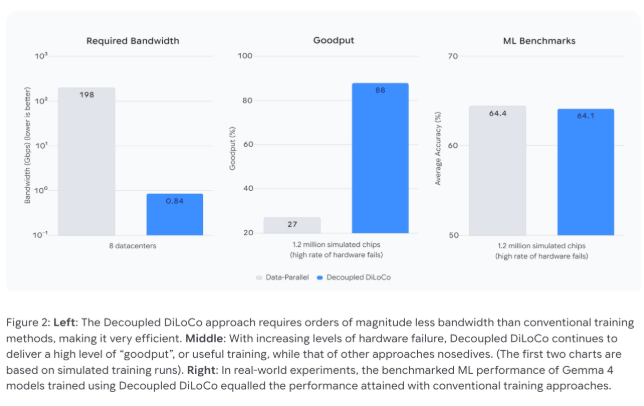
实验显示,在硬件故障率较高的情况下,解耦式 DiLoCo 仍可保持 88% 的集群利用率,而标准数据并行方法仅有 27%。同时,该方案将跨数据中心的带宽需求从 198 Gbps 大幅降至 0.84 Gbps,使依托现有商用互联网进行全球分布式训练成为现实。
更值得注意的是,解耦式 DiLoCo 具备自恢复能力。在混沌测试中,即使一个完整的学习单元失效,系统也能继续训练,并在该单元恢复后无缝回归整体。该方案还能适配多种硬件平台,支持不同代次的 TPU 在同一轮训练中协同工作,从而延长老设备的可用期,缓解硬件换代期间可能出现的产能压力。
划重点:
🌟 将训练分散到多个异步学习单元,整体更抗故障、训练更稳。
🌐 跨数据中心带宽需求降至 0.84 Gbps,全球分布式训练更易落地。
🔧 具备自恢复能力,故障时仍能高效训练,并支持异构硬件混合使用。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?