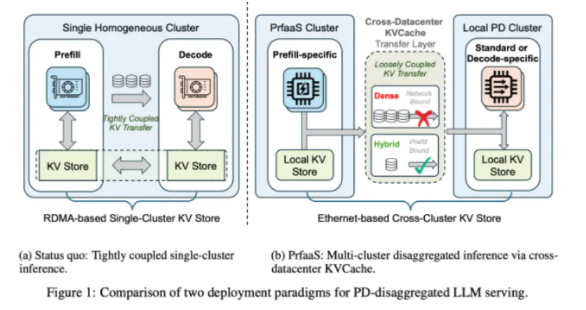


大语言模型(LLM)的推理性能瓶颈正被新技术逐步突破。近日,Moonshot AI(月之暗面)与清华大学研究团队联合提出了一种全新架构——**预填充即服务(PrfaaS)**。该方案通过更合理地划分与调度算力资源,针对大模型在数据中心落地时面临的硬件约束进行优化,显著提升了推理效率。

技术突破:将预填充与解码“精准拆分”
当前,大语言模型的推理大致包含两个差异化明显的阶段:
-
预填充阶段(Prefill):以计算为主,负责理解输入并构建键值缓存(KVCache)。
-
解码阶段(Decode):更依赖内存带宽,按序逐步生成输出。
传统服务架构通常把这两个阶段挤在同一数据中心甚至同一台服务器内处理。由于两者对硬件资源的侧重点不同,这种“捆绑式”处理经常造成计算与带宽资源分配失衡,从而引发服务拥堵。
核心创新:跨地域的高效协同
这一设计突破了物理距离限制,使预填充与解码能够在不同的数据中心并行协作。为确保传输高效稳定,PrfaaS引入了双时间尺度调度机制:可根据实时流量波动灵活调配资源,并配合精细的路由策略,保证长文本请求在传输过程中不因资源不均而产生额外延迟。
实测表现:吞吐量与延迟同步优化
研究显示,PrfaaS在实际应用中带来显著收益:
-
服务吞吐量提升54%,单位时间内可处理的请求明显增多。
-
响应延迟显著降低,用户侧首字生成更快。
-
资源利用率最大化,通过拆分计算、网络与存储子系统,规避了传统架构常见的拥塞难题。
此次 Moonshot AI 与清华大学的合作,不仅为大规模 AI 推理提供了新的工程路径,也为未来跨地域算力网络的建设奠定了技术基础。这种“预填充即服务”的模式,有望成为大模型迈向工业化应用的重要转折点。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?