

4月9日,字节跳动 Seed 团队官宣推出原生全双工语音大模型 Seeduplex,这意味着 AI 语音交互正从以往的“轮流对话”走向更贴近人类直觉的“实时自然沟通”。作为豆包端到端语音模型的一次重要升级,Seeduplex 的关键突破在于实现“一边听一边说”的同步处理架构,从底层让语音交流更加自然顺滑。目前,这项能力已在豆包 App 全量开放,完成了全双工技术从实验室到亿级用户规模化落地的跨越。

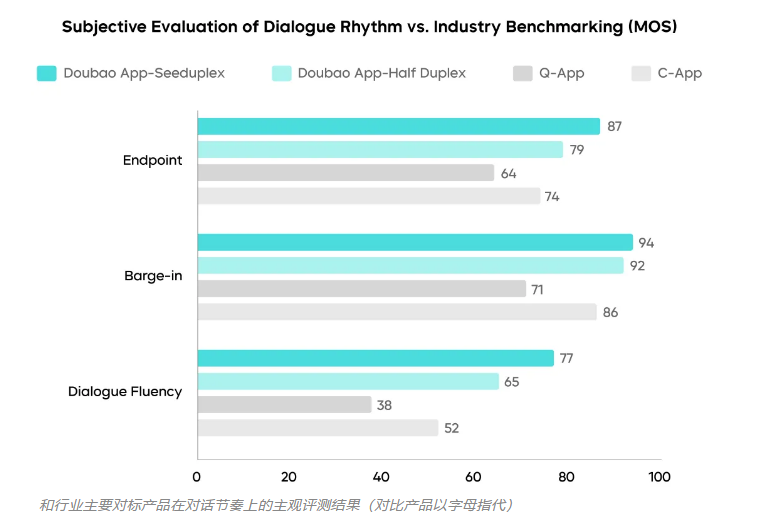
Seeduplex 采用语音与语义的联合建模,在复杂声场中显著增强抗干扰表现。与半双工方案相比,误回复率和误打断率下降50%;即使存在导航播报干扰、多人人声叠加或环境噪声,也能准确识别主用户意图并联动场景信息。
在对话节奏控制上,该模型引入动态端点判定技术,将端点延迟缩短约250ms,抢话比例降低40%,能更敏锐地区分用户的“思考停顿”和“对话结束”。在工程实现方面,团队通过投机采样与量化优化,在确保超低时延的同时解决了高并发下的卡顿难题,使通话满意度绝对提升8.34%。
Seeduplex 的落地不仅带来交互效率的跃升,也指向“感知—思考—执行”一体化的未来方向。随着后续视觉模态的加入,语音助手将向“听、看、想、说”多维协同的通用智能体深度进化,重塑智能硬件与多模态交互的行业标准。
项目主页:
https://seed.bytedance.com/seeduplex

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?