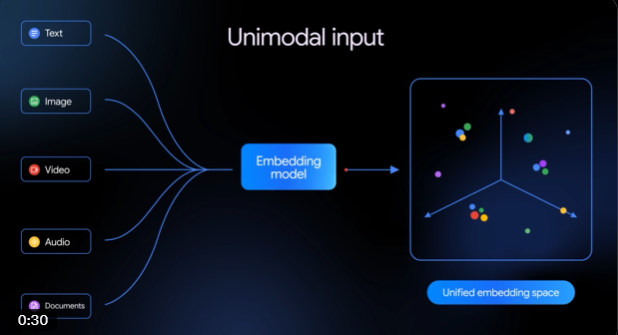


谷歌于2026年3月10日前后推出Gemini Embedding2,这是一款首款基于Gemini架构的完全多模态嵌入模型。目前已在Gemini API与Vertex AI开放Public Preview,开发者现在就能接入体验。
统一向量空间,打破模态隔阂
Gemini Embedding2的关键亮点在于,把文本、图片、视频、音频以及文档(PDF)等多种数据类型映射到同一个统一的嵌入向量空间。它实现了真正的跨模态检索与分类,支持100多种语言,让不同模态的数据能“用同一种语言”交流。

混合输入能力,精准捕捉语义关联
模型原生支持混合模态输入,例如图片+文字、视频+音频等组合。系统能够深入理解不同媒介之间的语义联系,而不是简单并列处理,多媒体内容理解能力因此大幅提升。
音频可原生处理,无需ASR转写
另一项重要升级是音频可直接进行嵌入。用户可输入原始音频文件,模型无需先做语音转文本(ASR),即可生成高质量向量。这大大简化了多模态处理流程,同时明显降低延迟与计算成本。
多场景应用,RAG进入新阶段
凭借统一架构与强大的跨模态能力,Gemini Embedding2可用于RAG检索增强生成、语义搜索、情感分析、内容聚类、法律证据检索等场景。编辑部认为,这一模型的发布将显著降低企业构建多模态AI应用的门槛,推动AI从“文本时代”迈向“全感知时代”。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?