

阿里通义实验室语音团队今日发布两款全新的语音生成模型:Fun-CosyVoice3.5 与 Fun-AudioGen-VD。这两款模型的亮点最大在于支持“FreeStyle”指令,用户无需复杂参数,仅用一句自然话描述,就能精准调控说话风格,或从零打造丰富的音频场景。

两款模型的功能侧重各不相同:
Fun-CosyVoice3.5:多语种复刻与更细致控制
该模型是在 CosyVoice 基础上的升级版,核心突破在于更强的语音表达“理解力”。
-
指令式生成:只需输入“语气更坚定”“语速放慢并带情绪起伏”等简单指令,输出会即时跟随调整。
-
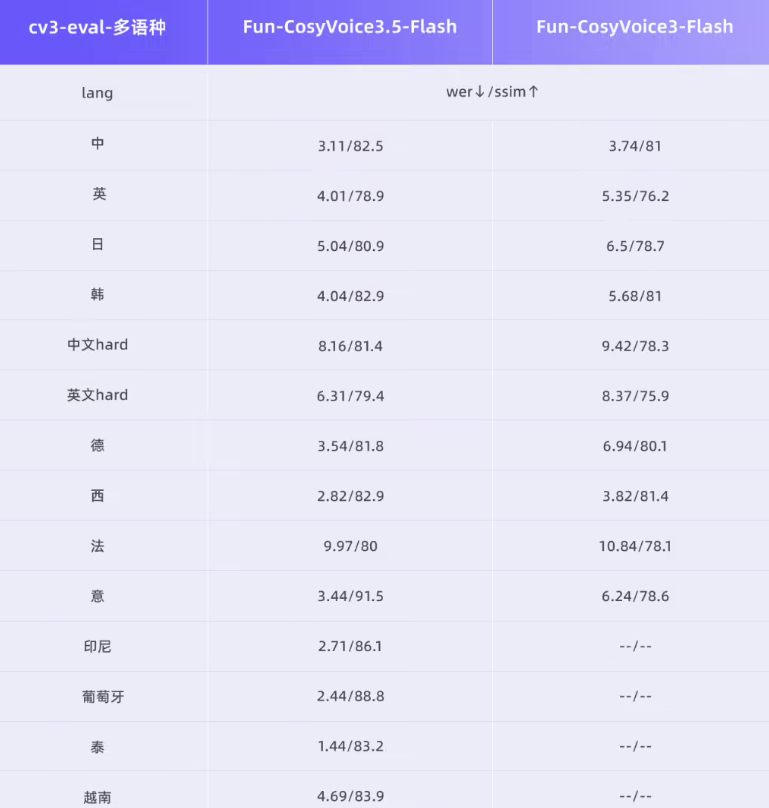
语种扩容:新增支持泰语、印尼语、葡萄牙语、越南语,在13种语言的转写准确率(WER)和音色相似度方面继续保持领先。
-
生僻字优化:专项训练后,生僻字读错率从15.2% 显著降至 5.3%。
-
性能提升:首包延迟降低 35%,实时互动更顺畅。
Fun-AudioGen-VD:全场景声音设计
这款模型更像“声音导演”,可按描述生成“人物 + 场景”的一体化音频。
-
音色定制:可指定性别、年龄、口音,甚至细化为“沙哑、磁性、低沉”等特质。
-
情绪与角色:能够模拟客服、播音员、儿童等角色,还能表现如“表面镇定但内心发颤”等复杂心理状态。
-
环境沉浸感:支持叠加背景音(如战场轰鸣、咖啡馆喧闹)与空间特效(如大教堂回声、水下听感),带来全方位的空间模拟。
通义实验室表示,这两款模型将进一步降低高质量语音创作门槛,为播客、游戏开发、影视后期等领域提供强力的 AI 支持。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?