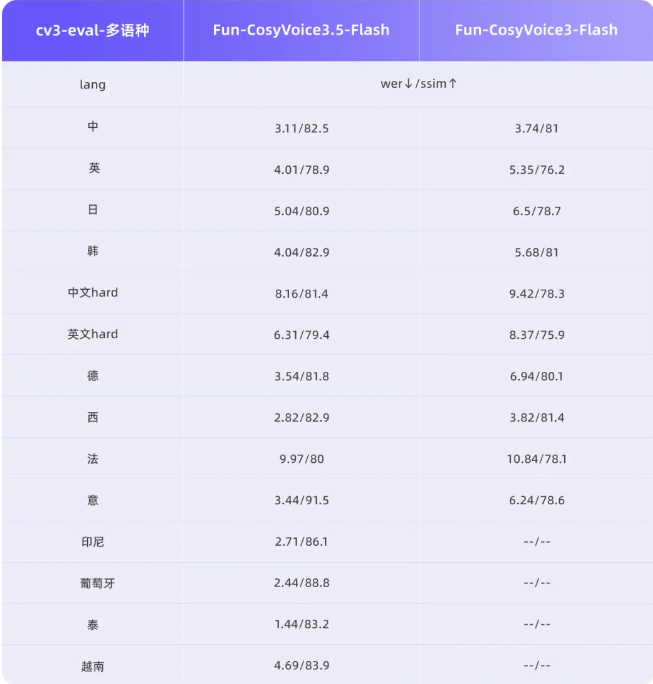


今天,


在技术架构与功能升级方面,
从行业趋势看,
API调用:https://help.aliyun.com/zh/model-studio/text-to-speech?spm=a2c4g.11186623.help-menu-2400256.d_0_3_2_0.d5536a31V2tEJP
文档:https://help.aliyun.com/zh/model-studio/cosyvoice-clone-api?spm=a2c4g.11186623.help-menu-search-2400256.d_2

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?