

大模型处理长文本的“内存焦虑”有望成为过去。近日,来自东京的AI初创公司Sakana AI发布两项突破性技术:Text-to-LoRA(T2L) 与 Doc-to-LoRA(D2L)。依托创新的“超网络”架构,模型无需重新训练,即可在不到一秒内“吸收”超长文档,或快速习得新任务。

长期以来,开发者面临两难:要么把长文档直接塞进上下文(反应变慢且非常耗内存),要么花不少成本给模型做微调。Sakana AI给出第三种选择——通过“一次性预训练”生成超小的LoRA权重插件,让模型以更低成本、更高效率完成适配。
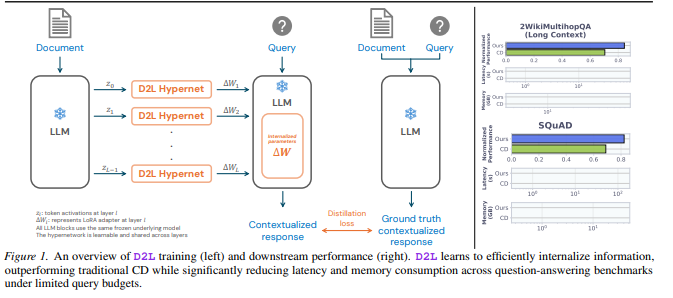
Doc-to-LoRA:12GB显存压到50MB
这次公布中最吸睛的就是D2L。传统方式处理12.8万Token(约十万字)时,模型需要超过12GB显存来保存信息;而用D2L,模型能把这些内容直接“消化”成不到50MB的插件。
-
速度快得惊人:以往消化文档要40到100秒,D2L只需不足1秒。
-
突破长度限制:可处理比原生上下文窗口长4倍的文本,并在“海量文本找关键”测试中保持近乎满分的准确率。
Text-to-LoRA:用自然话“定制”AI
T2L让模型更“听指挥”。用户只需用普通语言描述任务(例如“帮我解决复杂的数学竞赛题”),系统就能自动生成专属的性能增强插件。实验显示,这种适配器在数学与逻辑推理上,表现甚至超过针对该任务训练的独立模型。
跨模态惊喜:文字模型也能“看图”
研究团队还发现了一个意外收获:D2L具备强大的跨模态能力。把视觉信息映射到纯文本模型的参数中后,一个从未见过图片的文字模型,竟能以75.03%的准确率完成图像分类。
Sakana AI的这批成果,不仅显著降低了个人与企业定制私有AI的门槛,也为实现更轻量、更聪明的通用人工智能(AGI)开辟了新路径。
论文:https://arxiv.org/pdf/2602.15902

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?