

火山引擎正式推出全新的豆包大模型2.0(Doubao-Seed-2.0)系列,同时面向企业和开发者开放 API 服务。普通用户可以通过火山方舟体验中心,或在豆包 App 中选择「专家」模式进行体验。
这一代模型围绕大规模生产环境需求做了系统级升级,具备更高效的推理能力、更强的多模态理解和复杂指令执行能力,可以更从容地应对真实业务中的复杂任务。同时,相比业内顶尖模型,其推理成本大约降低了一个数量级,日均 Tokens 使用量相较刚上线时已经提升超过500倍。

豆包大模型2.0目前提供四款有明显差异的模型,方便按不同业务场景的时延和成本要求进行选择:Pro 版是旗舰型号,面向复杂深度推理、Agent 等高难度任务;Lite 版在整体能力上全面超越1.8版本,在实力提升的同时 Tokens 消耗更低,性价比更高;Mini 版主打速度快、成本低,能力水平接近1.6Pro 版;Code 版则针对开发者场景专门优化,更贴合真实编程环境,与 TRAE 搭配使用效果更好。
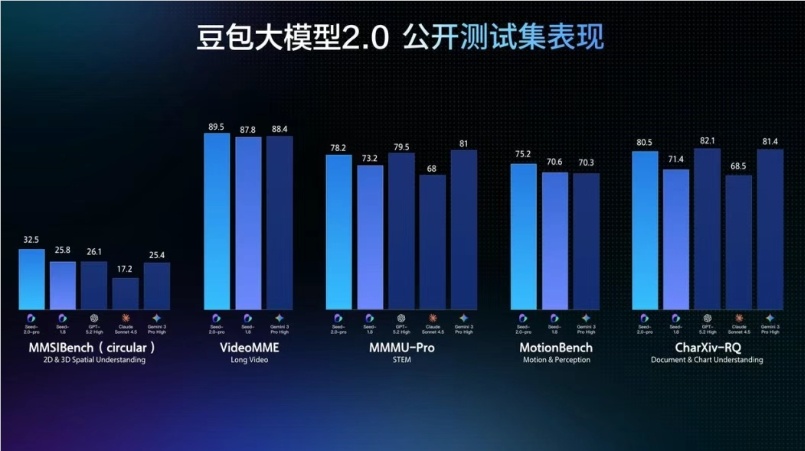
此次升级在多模态理解方面实现了全方位增强,在视觉理解能力上达到业内顶尖水准。Pro 版在空间理解 MMSIBench、动作理解 MotionBench、视频理解 VideoMME 等测评中的表现超过 Gemini3pro,在图表理解 CharXiv-RQ 测试中也有明显提升。
面向视频相关场景,模型加强了对时间序列和运动信息的理解,在 TVBench 等关键评测中取得领先成绩,EgoTempo 基准分数超过人类水平,在长视频测试中优于大多数顶尖模型,可支持实时视频流分析、主动讲解等交互方式,适用于健身、穿搭等陪伴类应用,还可以精细推理台球走位、识别各种运动动作并给出专业建议。
模型在 LLM 和 Agent 能力方面也有大幅提升,通过补充长尾领域的知识库,更好服务各类专业任务场景:Pro 版在 SuperGPQA 测试中的得分超过 GPT5.2,在 HealthBench 中拿下第一,在科学相关测评上与 Gemini3Pro、GPT5.2基本相当;在 HLE-text 测评中以54.2分领跑全球,在 IMO 测试中成绩超过 Gemini3pro,在工具调用、指令理解和执行等维度表现出色,在部分 STEM 基准场景上得分也高于 Gemini3Pro。
同时,模型在指令理解的一致性和可控性上进一步加强,更擅长处理长链路、多步骤任务,可以完成从“查找资料—归纳整理—输出结论”的连续工作流程,还能配合各类工具,完成从数据处理、内容创作到图片生成、排版呈现的一整套流程。基于该模型打造的智能客服 Agent,能够覆盖客户对话、问题分流、售后回访等完整服务链路。另外,Code 版模型可以稳定对接主流 IDE 工具,前端开发能力提升明显,支持自定义技能,与 TRAE 组合使用可以显著提高开发效率,只需约5轮对话就能搭建出类似“AI 春节庙会”这样复杂的 Web 应用,相关素材已经开源。
针对 Agent 时代 Tokens 用量激增的问题,火山引擎同步推出了 Coding Plan 套餐包,开发者可以在火山方舟中调用该模型,新用户首月最低只需 8 元就能体验,实现不同编程任务与模型能力的精细匹配。

















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?