

1月30日,延续空间感知模型、具身大模型与世界模型的“三连发”,蚂蚁灵波科技今日宣布开源具身世界模型 LingBot-VA。LingBot-VA 首次提出自回归的视频-动作世界建模方案,把大规模视频生成模型与机器人控制深度结合,模型在生成“下一步世界状态”的同时,会直接推演并给出对应的动作序列,让机器人能像人一样“边推演、边行动”。
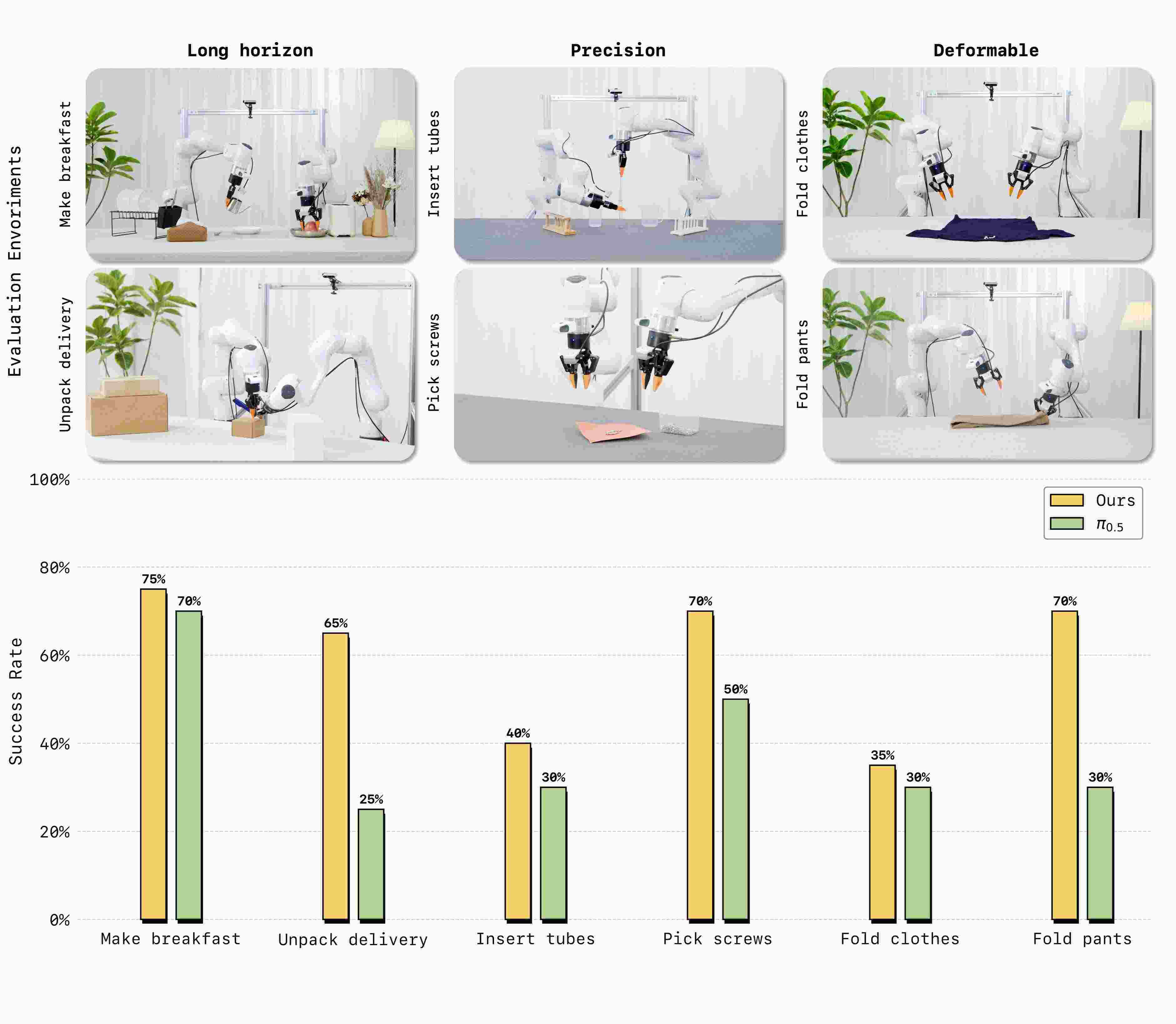
在真机评测中,LingBot-VA 展现出对复杂物理交互的强适应性。面对长时序任务(制作早餐、拾取螺丝)、高精度任务(插入试管、拆快递)以及柔性与关节物体操控(叠衣物、叠裤子)这三类共六项高难挑战,仅需30~50 条真机演示数据即可完成适配,且任务成功率较业界强基线 Pi0.5 平均提升约20%。

(图说:在真机评测中,LingBot-VA 在多项高难操作任务上表现超过业界标杆 Pi0.5)
在仿真评测中,LingBot-VA 在高难度双臂协同操作基准 RoboTwin2.0 上首次将成功率提升到超过 90%,在长时序终身学习基准 LIBERO 上取得 98.5% 平均成功率,均刷新了行业纪录。

(图说:LingBot-VA 在 LIBERO 与 RoboTwin 2.0 仿真基准测试中刷新现有 SOTA)
据悉,LingBot-VA 采用 Mixture-of-Transformers(MoT)架构,让视频处理与动作控制实现跨模态融合。借助独特的闭环推演机制,模型在每一步生成时都会纳入真实世界的实时反馈,确保持续生成的画面与动作不偏离物理现实,从而驱动机器人完成高难复杂任务。
为突破大规模视频世界模型在机器人端侧落地的计算瓶颈,LingBot-VA 设计了异步推理管线,将动作预测与电机执行并行处理;同时引入基于记忆缓存的持久化机制与噪声历史增强策略,让推理时用更少的生成步骤即可产出稳定、准确的动作指令。这些优化使得 LingBot-VA 既有大模型的理解深度,又具备真机低延迟控制的响应速度。
蚂蚁灵波表示,承接前几日开源发布的 LingBot-World(模拟环境)、LingBot-VLA(智能基座)与 LingBot-Depth(空间感知),LingBot-VA 探索出一条“世界模型赋能具身操作”的新路径。蚂蚁集团将持续依托 InclusionAI 社区开源开放,与行业共建具身智能基础能力,加速构建深度融合开源开放、并服务真实产业场景的 AGI 生态。
目前,LingBot-VA 的模型权重与推理代码已全面开源。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?