

DeepSeek 发布了下一代文档识别模型 DeepSeek-OCR2。它在视觉编码器设计方面带来显著升级,旨在补齐传统模型在处理复杂排版文档时逻辑理解不足的短板。

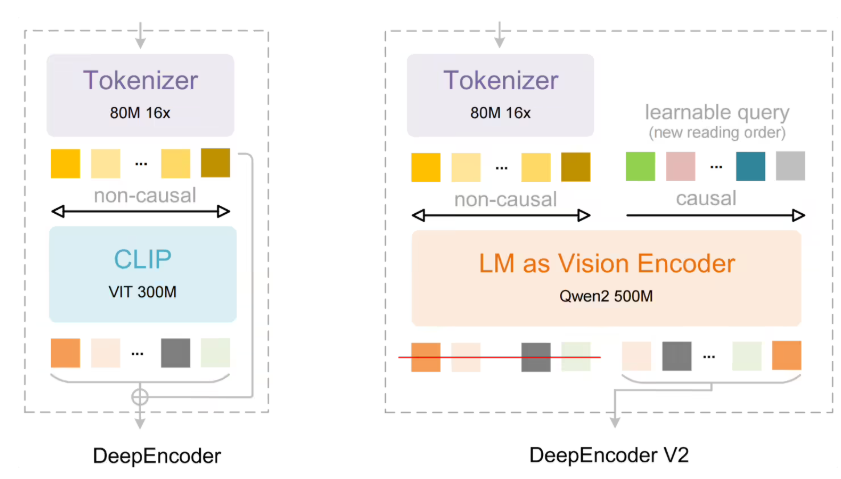
DeepSeek-OCR2 的核心卖点是自研的 DeepEncoder V2 编码器。不同于传统视觉模型沿用从左到右、从上到下的固定栅格处理路径,新模型提出“视觉因果流”概念。它会根据页面语义动态安排信息的处理顺序,先对视觉内容做智能重排,再进行文字识别,使机器的阅读过程更符合人类在表格、公式及复杂文档中的理解方式。
在架构层面,模型延续高效的编解码思路:图像先由 DeepEncoder V2 完成语义建模与顺序重组,随后交给 MoE(混合专家)语言模型进行解码。实测结果显示,在 OmniDocBench v1.5 基准中,DeepSeek-OCR2 的总体得分达到 91.09%,相比前代提升 3.73%。在阅读顺序的准确度方面,编辑距离明显下降,表明模型对内容结构的复原能力更强。
同时,DeepSeek-OCR2 在实用场景中也更稳健:在 PDF 批处理与在线日志数据的测试中,重复识别率显著降低。这意味着在保持低算力成本的前提下,模型能提供更高质量且更具逻辑性的识别输出。
划重点:
-
语义驱动的动态排序: DeepSeek-OCR2 借助“视觉因果流”,突破固定栅格的读取顺序,实现按语义组织的动态阅读。
-
性能显著跃升: 在权威基准测试中,总体表现提升 3.73%,阅读顺序更精准,编辑距离更低。
-
高效 MoE 设计: 模型延续 MoE 解码方案,在不增加算力负担的情况下,进一步提升识别精度与稳定性。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?