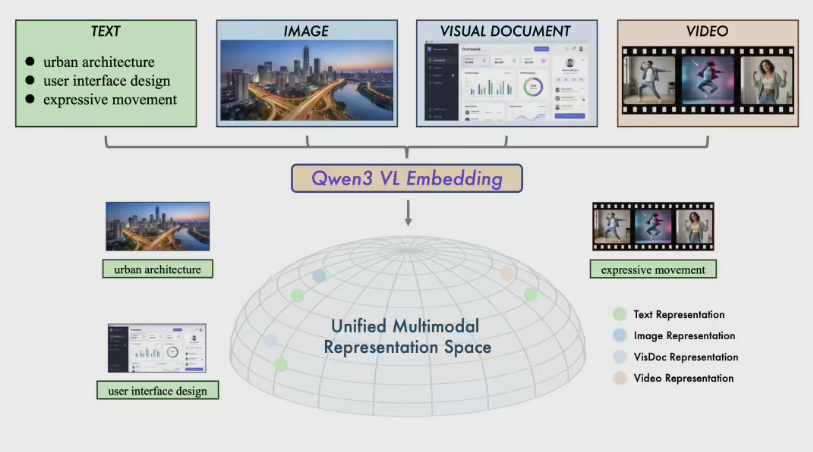


当文字、图片、视频、图表甚至应用界面被统一“读懂”并能精准对应,多模态信息检索的边界正在被重塑。今天,阿里通义实验室正式开源Qwen3-VL-Embedding与Qwen3-VL-Reranker两款模型。它们基于强大的Qwen3-VL多模态底座打造,面向跨模态理解与高效检索,让多模态搜索从“关键词匹配”迈向“语义对齐”的新阶段。
这两款模型并非孤立,而是协同工作的智能检索组合。Qwen3-VL-Embedding采用高效的双塔架构,可将文本、图片、可视化文档(如代码截图、数据图表、App界面)以及视频等异构内容,分别编码为统一高维语义空间中的向量。这意味着,不管用户输入是一段文字描述、一张产品图片,还是一段短视频,系统都能把它们映射到同一语义坐标系,实现毫秒级的跨模态相似度计算与海量数据召回。

而Qwen3-VL-Reranker则承担“精细打磨”的关键环节。它采用单塔交叉注意力架构,对Embedding初步召回的结果进行深度重排序。面对“图文查询匹配图文文档”或“用视频片段检索相关文章”等复杂任务时,Reranker会将查询与候选联合编码,通过交叉注意力机制,逐层分析二者在语义、细节以及上下文逻辑上的深层关联,最终输出精确的相关性分数。“Embedding快速召回 + Reranker精排”的两阶段流程,显著提升检索结果的准确度与相关性。

技术表现最具说服力。在MMEB-v2和MMTEB等权威多模态基准测试中,Qwen3-VL系列成绩亮眼。其8B版本的Embedding模型在MMEB-v2上超越了所有已知开源模型及主流闭源商业服务;Reranker模型在视觉文档检索任务(包括JinaVDR、ViDoRe v3)中持续领先,8B版本在多数子项中名列前茅。更为难得的是,该系列延续了Qwen3-VL的多语言能力,支持30+语言,并提供灵活的向量维度选择、指令微调以及高性能量化版本,显著降低开发者集成门槛。
此次开源不仅是技术成果的释放,更意味着多模态AI基础设施的走向成熟。过去,图文检索、视频理解、文档分析往往需要各自独立的模型和流程;如今,Qwen3-VL“双子星”提供了统一、高效且开源的解决方案,让开发者能够在一个框架内处理几乎所有混合模态内容。随着真实世界数据愈发以多模态形式涌现,这套工具有望加速推动搜索引擎、内容平台、企业知识库以及智能助理的下一代进化——让机器真正“看懂”并“理解”我们所见、所写、所拍的一切。
项目地址:https://github.com/QwenLM/Qwen3-VL-Embedding

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?