

当全球AI竞争还集中在自回归大模型(如GPT-5、Gemini)之际,一家新创团队正以不同的底层设计切入赛道。由斯坦福大学教授Stefano Ermon创办的Inception,近日拿下5000万美元种子轮融资:Menlo Ventures领投,微软M12、英伟达NVentures、Snowflake Ventures、Databricks Investment与Mayfield跟投,吴恩达(Andrew Ng)和Andrej Karpathy以天使身份加入,投资阵容可谓强大。
Inception的核心选择,是把最早用于图像生成的扩散模型(Diffusion Models)全面带到文本与代码场景,向当下主流的自回归路线发起挑战。Ermon表示,GPT、Gemini这类模型采用“逐词预测”,必须串行生成,速度与效率受到限制;而扩散模型通过多轮并行迭代整体优化输出,在处理大型代码库或长文档时更有优势。
这一思路已落地为产品:公司同步发布其最新模型Mercury,面向软件开发使用,目前已接入ProxyAI、Buildglare、Kilo Code等多款开发者工具。实测显示,Mercury在代码补全、重构和跨文件理解等任务中,推理吞吐突破1000 token/秒,显著快于主流自回归模型。“我们的架构生来就适合并行,”Ermon强调,“更快、更省、对算力成本也更友好。”
为什么扩散模型适配代码?
代码不同于自然语言——结构更严密、依赖全局上下文,且常涉及跨文件关联。自回归模型在这种任务中因为“逐字生成”容易忽视整体一致性;扩散模型从“噪声”出发,通过多轮全局调整逼近目标,更贴合高度结构化的数据。同时,其并行计算特性可充分吃满GPU/TPU集群,显著降低延迟与能耗,直面当下AI基础设施的高成本问题。
巨头为何青睐?
在训练与推理成本持续上行的大背景下,效率成了关键赛点。微软、英伟达、Databricks等投资方正搭建各自的AI开发栈,急需高性能、低开销的模型底座。Inception的路径,可能为大模型商业化提供一条“省算力、高吞吐”的新方案。
业内观点认为,Inception的崛起意味着AI架构探索进入深水区——当单纯堆参数的收益趋于减弱,底层范式的创新将成为破局关键。若扩散式LLM能在代码、科研、金融等高价值场景持续证明优势,这场源自斯坦福实验室的技术变革,有望重塑生成式AI的未来版图。







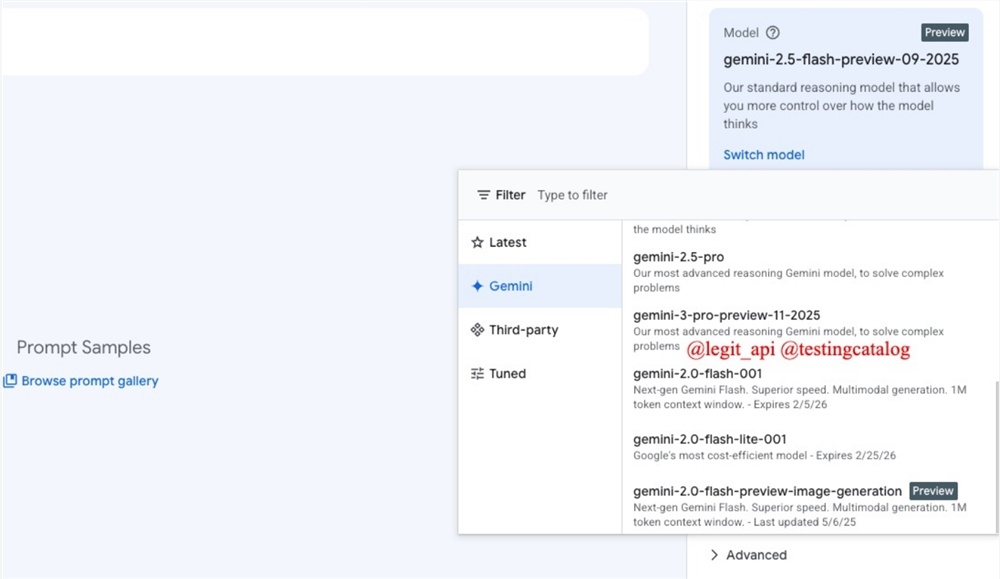








用户38505528 1个月前0
粘贴不了啊用户12648782 2个月前0
用法杂不对呢?yfarer 2个月前0
草稿id无法下载,是什么问题?