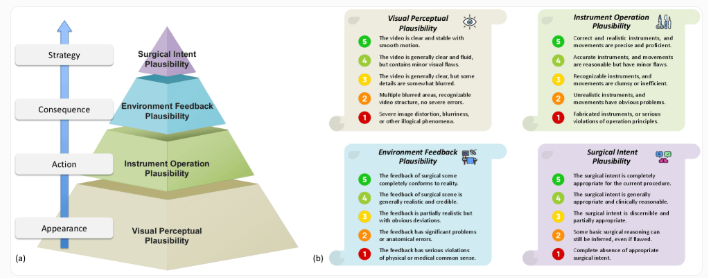


近期,研究团队对谷歌最新的视频生成模型 Veo-3 进行评估。结果表明,它能合成极其逼真的手术画面,但对医疗操作的理解明显不够。实验里,团队给出一帧手术图像,要求 Veo-3 预测随后 8 秒的手术发展。为此,研究者搭建了名为 SurgVeo 的评测基准,收录 50 段真实的腹腔与脑外科手术视频。

研究小组邀请了四位经验丰富的外科医生对 AI 生成的视频进行独立评分,评分维度涵盖视觉真实性、器械使用是否合理、组织反应以及手术逻辑性。尽管医生们对 Veo-3 的画面质量评价很高,直言“清晰得令人震惊”,更细致的分析却显示其医学逻辑表现不佳。在腹腔手术测试里,Veo-3 的视觉合理性得分为 3.72 分,但器械操作仅 1.78 分,组织反应 1.64 分,而手术逻辑性更是低至 1.61 分。
在神经外科场景中的表现更为逊色:其在 8 秒后手术逻辑性的评分仅 1.13 分。研究团队发现,超过 93% 的错误来自医学逻辑层面,例如“凭空出现”的手术器械以及不符合生理规律的组织反应。即便给模型更多上下文信息,如手术类型和具体操作阶段,也未能明显改善结果。

研究指出,现阶段的视频生成 AI 距离真正理解医疗操作还有不小差距。虽然未来这些系统可能用于医生培训与术前规划,但目前的模型尚未达到安全可靠的应用门槛。研究团队计划开源 SurgVeo 数据集,推动学术界提升 AI 在医学理解方面的能力。同时也提醒,在医学培训中使用此类生成视频风险较高,可能带来误导性学习与错误的手术技巧。
划重点:
🌟 Veo-3 能合成逼真的手术画面,但医学逻辑理解不足。
🔍 超过 93% 的错误源于医学逻辑问题,严重影响视频准确性。
📈 团队计划开源数据集,促进 AI 在医学理解方面的进步。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END














用户38505528 1个月前0
粘贴不了啊用户12648782 2个月前0
用法杂不对呢?yfarer 2个月前0
草稿id无法下载,是什么问题?