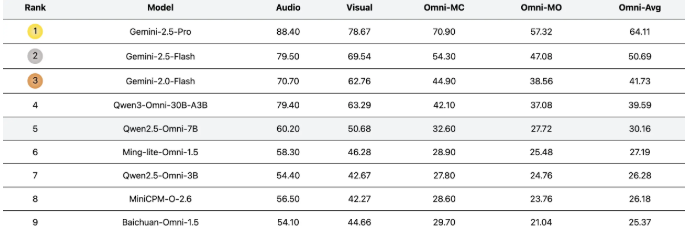


近日,美团 LongCat 团队推出全新评测基准 UNO-Bench,旨在以系统化方式检验模型在不同模态下的理解与表现。该基准覆盖44类任务与5种模态组合,力求全面反映模型的单模态与全模态能力。
UNO-Bench 的亮点在于其多样而扎实的数据集。团队精挑了1250个全模态样本,跨模态可解率高达98%;同时补充了2480个强化后的单模态样本。数据设计贴近真实应用,尤其在中文语境下表现突出。值得注意的是,经过自动化压缩处理后,运行效率提升约90%,并在18个公开基准上保持约98%的一致性。

为更好地衡量模型的复杂推理能力,UNO-Bench 引入了创新的多步骤开放式问答形式,并结合通用评分模型,能够自动评估六类题型,整体判分准确率可达95%。这一评测思路为多模态模型测评带来新的参考范式。

目前,UNO-Bench 重点面向中文应用场景。团队正积极寻找合作伙伴,共同推进英文及多语种版本。感兴趣的开发者可通过 Hugging Face 获取 UNO-Bench 数据集,相关代码与项目文档已在 GitHub 开源。
随着 UNO-Bench 的发布,多模态大语言模型的评测标准有望进一步完善,不仅为研究人员提供强有力的工具,也将助推行业整体发展。
项目地址:https://meituan-longcat.github.io/UNO-Bench/

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END














用户38505528 1个月前0
粘贴不了啊用户12648782 2个月前0
用法杂不对呢?yfarer 2个月前0
草稿id无法下载,是什么问题?