

分类
平台
排序
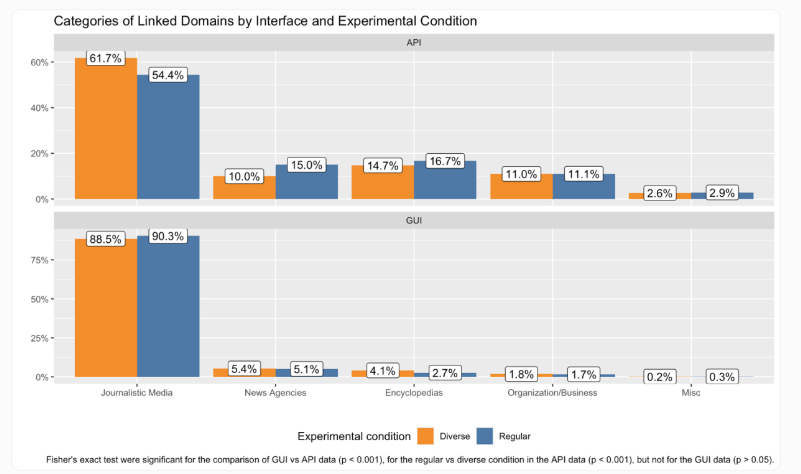
ChatGPT新闻推荐现“两套标准”:API与网页版差异明显
汉堡大学与莱布尼茨媒体研究所对德语区超过24,000条与新闻相关的 AI 答复开展了为期五周的监测,结果显示,用户通过不同入口使用 ChatGPT,会显著影响其推荐的新闻来源。研究团队进一步确认,网...

DeepSeek‑Math‑V2 发布:首个开源模型以 IMO 金牌水准亮相
DeepSeek 今日官宣推出 DeepSeek‑Math‑V2。这一拥有 6850 亿参数的混合专家(MoE)模型,成为全球首个以开源形式达到国际数学奥林匹克(IMO)金牌水准的数学推理大模型。它基于 DeepSeek‑V3....

AI浪潮逼近:麦肯锡称全球或有多达8亿岗位被替代
随着人工智能不断提速发展,加州大学伯克利分校教授 Stuart Russell 提醒:几乎所有职业都会被 AI 影响,连首席执行官也不例外。麦肯锡全球研究院的报告表示,到2030年,全球可能有多达8亿个岗...

智驾座舱双升级!阿维塔 AVATR.OS 5.0 全量推送:MoLA 大模型上车,首批接入华为 ADS 4.1
盼望已久的重磅版本来了。2026年2月11日,阿维塔官宣面向全系车型开启 AVATR.OS5.0.0 正式推送。本次迭代的核心是深度融入 AI 大模型能力,并同步升级至华为前沿的智能驾驶系统。MoLA 大模型:...

元宝携混元发布2025年度报告:超过七成用户偏好快思考模式
近日,元宝官方发布了2025年在元宝平台使用混元大模型的年度报告。“元宝”依托混元系列模型,实现了AI能力的多维升级。在元宝平台上,混元同时提供“快思考”和“深度思考”两种模式:超过七成...

夸克AI眼镜迎来首个OTA:AI实力再提升,新增图文备忘录等五大功能
12月31日,搭载千问AI助手的夸克AI眼镜迎来首次OTA升级,整体AI体验再进阶。新加入录音纪要、图文备忘录、基于大模型的多意图理解与执行、蓝环支付、社区服务等五项能力,并同步优化了用户常用...
Meta 正式宣布裁撤外包审核员:AI 将全面接手内容审查体系
处在内容监管与技术升级的关口,Meta 做出了一次大胆的调整。本周,Meta 正式公布一项里程碑计划:未来几年将用自研的 AI 审核系统,逐步取代当前依赖的第三方外包人类审核员。这意味着,长期为...
中国信通院人工智能研究所携手发布《大模型一体机应用研究报告(2025年)》
中国信息通信研究院(“中国信通院”)人工智能研究所以及中国人工智能产业发展联盟共同发布了《大模型一体机应用研究报告(2025年)》。报告围绕大模型一体机的技术演进、产业动向与应用实践进...

字节跳动上线扣子 2.0 AI Agent 平台,Agent Skills 成为亮点
字节跳动旗下的 AI Agent 开发平台“扣子”(Coze)迎来 2.0 大版本。此次升级意味着,AI 智能体从简单的“一问一答”,迈向可进行长期规划执行、深度职场办公、以及云端协作开发的综合平台。在...
保护未成年用户:OpenAI与Anthropic拟推AI年龄识别功能
伴随全球对青少年在线安全的关注持续升温,两大人工智能公司OpenAI和Anthropic于本周四宣布,将采取更主动的举措来识别并保护未成年用户。两家企业计划借助 AI 模型推测用户年龄,并针对...

AI歌曲冲上全球榜首,传统乐坛遭遇强烈冲击
本周,三支由人工智能创作的单曲接连在各大榜单表现亮眼,强势登顶 Spotify 与 Billboard 的热门榜单。其中,Breaking Rust 的《Walk My Walk》和《Livin’ on Borrowed Time》在美国 Spotify“...
美团光年之外首发!Tabbit AI 浏览器开放公测:聚合全网大模型,智能代理包办“脏活累活”
浏览器已不再只是用来浏览网页的“窗口”,正一步步变成能办事的“智能同事”。2026 年 3 月 2 日,美团 旗下 光年之外(GN06) 团队宣布,其首款 AI 原生浏览器 Tabbit 面向公众开放测试。作为...


