

最近,Mistral AI 推出 Voxtral 系列模型,把文本与音频处理整合在一起,能够覆盖多种应用场景。该系列包含两款模型:Voxtral-Mini-3B-2507 和 Voxtral-Small-24B-2507。前者是一款优化过的 3 亿参数模型,适合快速语音转写和基础多模态理解;后者拥有 240 亿参数,支持更复杂的音频-文本智能与多语言处理,非常适合企业级使用。

两款模型均可处理长达 30 至 40 分钟的音频上下文,具备自动语言检测功能,并支持最多 32,000 个标记。它们以 Apache 2.0 许可证发布,适合商业与研究项目,拥有高效的多模态处理能力,可在同一流程中同时理解口语与书面内容。
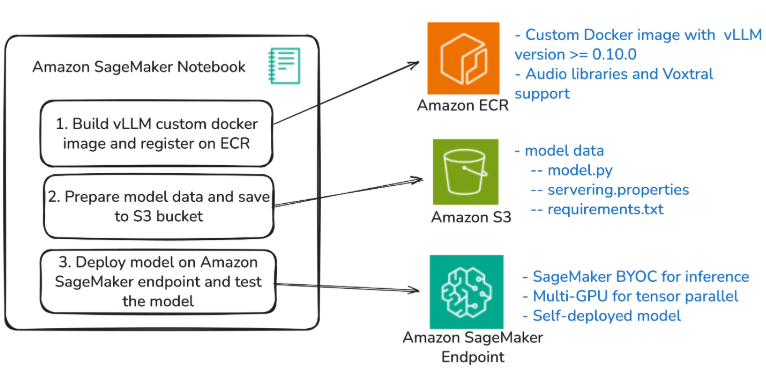
本文演示如何通过 vLLM 与“自带容器(BYOC)”的方式,在 Amazon SageMaker 端点上托管 Voxtral 模型。vLLM 是一款高性能库,能够更好地管理大模型的内存,并支持跨多块 GPU 的张量并行。SageMaker 的 BYOC 功能允许使用自定义容器镜像进行部署,让模型优化与版本控制更加灵活。
整个部署流程以 SageMaker 笔记本环境为核心控制点,负责构建并推送自定义 Docker 镜像到 Amazon 弹性容器注册中心(ECR),同时管理模型的配置与部署工作流。另有 Amazon S3 用于存放 Voxtral 所需的关键文件,实现配置与容器镜像的模块化分离。
该方案适配多种用例:仅文本的传统对话式 AI、精准的音频文件转写,以及音频与文本结合的复杂多模态应用。用户只需更新配置,即可在 Voxtral-Mini 与 Voxtral-Small 之间无缝切换。借助这些多模态能力,Voxtral 能为音频与文本处理提供更灵活、更高效的服务。
划重点:
📌 Voxtral 同时覆盖文本与音频处理,适配多种应用场景。
🔧 在 Amazon SageMaker 通过自定义容器托管 Voxtral,部署更灵活。
💡 可用于文本处理、语音转写与多模态复杂应用。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?