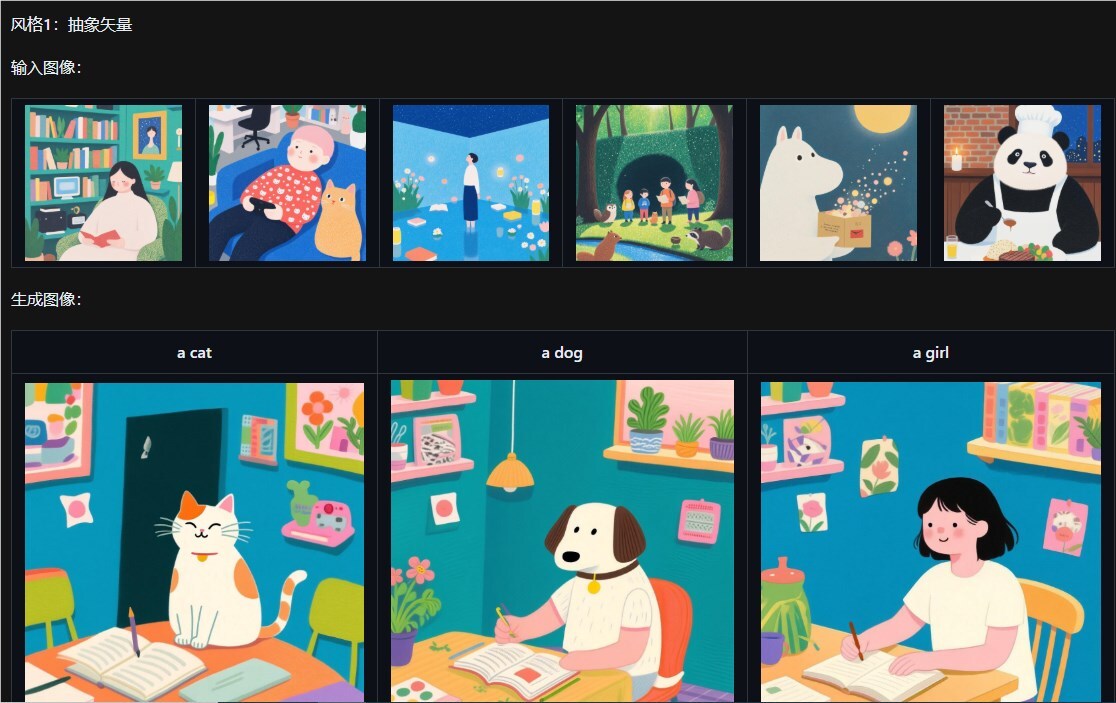


在AI图像生成圈里,最近冒出一项重磅新技术:Qwen-Image-i2L。这是阿里通义实验室推出的开源工具,能把任意一张图片快速变成可微调的LoRA(低秩适配)模型,大幅降低个性化风格迁移的难度。

不需要海量数据集或昂贵算力,用户只要上传一张图,就能生成轻量级LoRA模块,并可无缝接入其他生成模型,轻松完成“单图风格迁移”。这项创新很快在AI社区引发热议,被称为“AI艺术生产的临门一脚”。
核心亮点:从单图到LoRA,一键开启个性化生成
Qwen-Image-i2L的关键在于独特的图像拆解机制。它结合SigLIP2、DINOv3和Qwen-VL等多模态特征提取体系,把输入图片智能分解为“风格、内容、构图、色调”等核心视觉元素。随后将这些可学习特征高效压缩,形成体积小巧的LoRA模块——平均只需数GB空间,却能抓住图片的精髓。
举个例子:你上传一幅印象派油画,系统会提取柔和的笔触和偏暖的色调;或放上一位艺术家的肖像,马上生成人物风格的LoRA。生成的模块可以直接加载到Stable Diffusion或其他扩散模型里,继续用于创作。这既简化了传统训练流程(过去往往需要20+张图片和成片GPU),也实现了“一键学习”,让AI艺术创作从专业门槛走向大众可玩。

社区反馈显示,这项能力特别适合做快速原型和风格试验。开源发布后,开发者已开始探索其在产品可视化和数字艺术等场景的用法,预计会加速AI工具的商业落地。
四种模型变体,匹配多样使用场景
– 风格模式(2.4B参数):侧重美学特征提取,适合艺术画风迁移,比如把水彩气质注入新图片。
– 粗粒度模式(7.9B参数):同时捕捉内容与风格,适合整体场景重构,例如快速生成建筑或景观的不同版本。
– 精细模式(7.6B参数):支持1024×1024高分辨率的细节增强,常与粗粒度模式搭配,提高纹理和边缘的精度。
– 偏见模式(30M参数):让输出更贴近Qwen-Image原生风格,避免偏差,适合需要品牌统一性的企业级应用。
这些变体均按Apache 2.0许可证开源,用户可在Hugging Face或ModelScope平台免费下载。测试结果显示,在复杂文本渲染和语义编辑的基准上,Qwen-Image-i2L胜过多数开源竞品,与不少闭源模型也旗鼓相当。
技术底层与潜在挑战:高效但要警惕过拟合
Qwen-Image-i2L的实力来自多模态基础模型Qwen-Image(20B参数,MMDiT架构)。该模型在GenEval、DPG等基准中表现突出,尤其在中英双语文本渲染方面领先。配合FlowMatchEuler调度器,它能高效推理,平均生成时间压缩到数秒。
不过,社区也指出,“单图学习”虽然很突破,但也存在问题:从单一2D图像提炼复杂的3D逻辑,可能导致过拟合;在更丰富的场景下,输出稳定性还有提升空间。开发者建议结合多步蒸馏或辅助数据集,以进一步增强鲁棒性。
未来展望:AI个性化时代的加速器
Qwen-Image-i2L的推出,意味着AI图像工具正从“通用生成”迈向“即时定制”。它不仅赋能创作者,也为电商、游戏、影视等行业注入新活力。随着生态不断完善,这类工具有望催生更多“一键创新”的应用,推动开源AI走向更普惠。
模型下载地址:https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-i2L/summary

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?