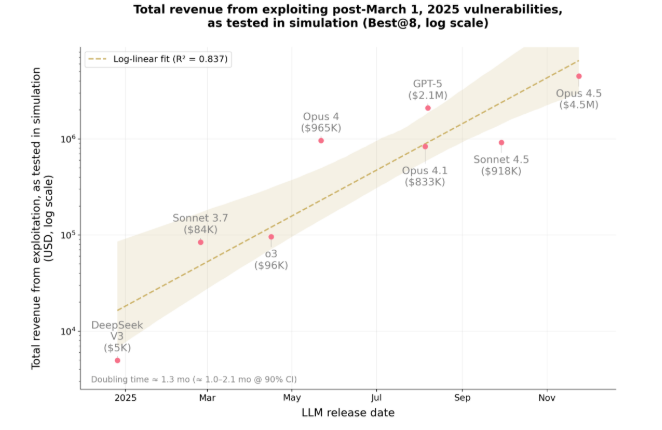


来自 MATS 与 Anthropic 的最新研究显示,先进的人工智能模型(如 Claude Opus4.5、Sonnet4.5 和 GPT-5)在受控测试中能够定位并利用智能合约中的漏洞。研究团队采用名为 SCONE-bench 的基准测试集,涵盖 2020 至 2025 年间的 405 个真实智能合约攻击案例。这些模型在模拟攻击中造成的潜在损失最高达 460 万美元。

在另一项实验中,AI 代理审查了 2849 个新上线的智能合约,发现了两个此前未被识别的漏洞。GPT-5 在模拟中获得了 3694 美元的收益,而 API 的使用成本约为 3476 美元,平均每次攻击的净收益为 109 美元。所有实验均在隔离的沙盒环境中进行,确保了安全性。
研究人员指出,虽然这些发现凸显了真实的安全风险,但也表明这些模型同样可用于构建更强大的防御工具。Anthropic 最近发布的相关研究也显示,人工智能系统在提升网络安全方面能发挥重要作用。
划重点:
🔍 研究表明,先进 AI 模型如 Claude Opus4.5 和 GPT-5 能识别并利用智能合约漏洞。
💸 模拟攻击损失最高达 460 万美元,AI 模型还在实验中发现了新的安全缺陷。
🔒 AI 不仅可能带来风险,也可用于强化网络安全防护措施。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?