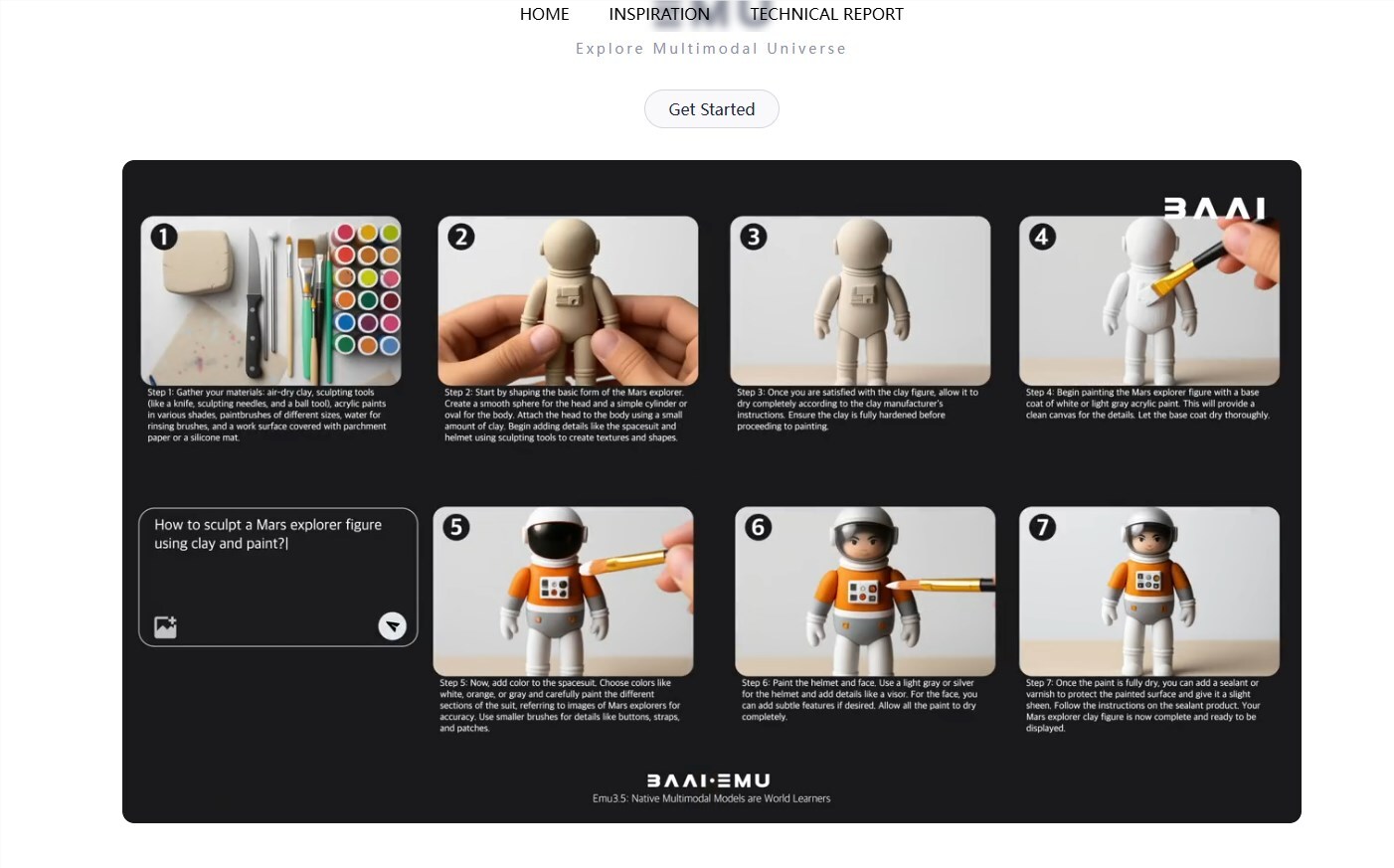


12月4日,北京智源人工智能研究院正式发布新一代多模态大模型Emu3.5,被称为“真正懂物理世界的AI”。与过去图像、视频、文本模型各自独立不同,Emu3.5首次实现“世界级统一建模”,让AI从“会画画、会写字”升级到真正“懂世界”。

传统AI的关键短板:不懂物理、不懂因果
过去大多数图像生成模型虽然看起来很逼真,却缺少对真实世界规律的理解:物体不会无故漂浮,重力、碰撞、运动轨迹在它们眼里几乎是“黑箱”。就算是顶级视频生成模型,也常会出现动作突兀、逻辑断层的问题。根源在于:它们学到的是“像素表面”,而不是“世界运转的规则”。
Emu3.5的核心突破:预测“世界的下一秒”
Emu3.5彻底改变了这一点。研究团队把图像、文本、视频统一编码为同一种Token序列,模型只做一个最纯粹的任务——NSP(Next State Prediction,预测下一个世界状态)。
通俗来说:
– 不管输入是图片、文字还是视频帧,在Emu3.5看来都是“世界当前状态”的不同表达;
– 模型始终只做一件事:预测“下一秒世界会如何变化”;
– 下一秒可能是文字→自动续写对白;
– 下一秒可能是画面→自动生成合理动作;
– 下一秒也可能同时包含视觉+语言的变化→推演完整的世界演化。
统一Token化:图像、文字、视频彻底打通
Emu3.5最大的技术亮点,是把所有模态统一成同一套“世界积木”。模型不再区分“这是一张图”“这一句话”或“视频的一帧”,所有信息都被离散为Token序列。依靠海量数据训练,模型学会了跨模态的因果关系与物理常识,真正具备了“世界级理解力”。
从“像素搬运工”到“世界模拟器”
业内专家认为:Emu3.5标志着多模态大模型从“生成时代”迈入“世界模型时代”。未来基于Emu3.5,不仅能生成更自然的长视频、实现交互式图像编辑,还可能直接用于机器人具身智能、自动驾驶仿真、现实物理预测等更高阶场景。
独家点评
当很多厂商还在卷参数、卷分辨率、卷视频时长时,北京智源把问题拉回到本质——“AI是否真正理解世界”。Emu3.5用最简单的“预测下一个Token”统一了所有模态,却带来了最深层的能力跃迁:从“像”到“对”。这一次,中国团队用原创范式引领了全球AI的新方向。
真正的世界模型,已经到来。
你准备好迎接“可预测的下一秒”了吗?
官网地址:https://zh.emu.world/pages/web/landingPage
体验地址:https://zh.emu.world/pages/web/login

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?