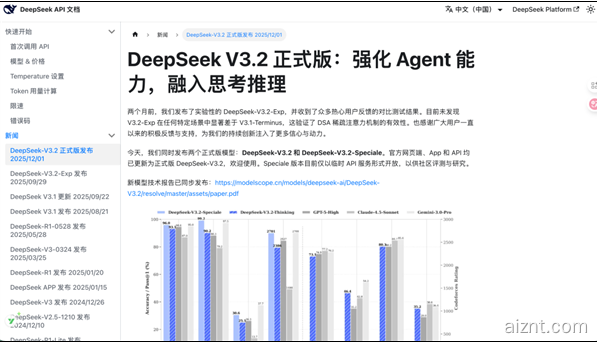


DeepSeek 正式上线 V3.2(标准)与 V3.2-Speciale(深思版),官方测试结果显示:
– 在 128k 上下文下,V3.2 与 GPT-5 各有胜场
– V3.2-Speciale 在 MMLU、HumanEval 等基准上与 Gemini3Pro 持平,IMO2025 盲测拿到金牌线 83.3%
“转正稀疏注意力”(DSA)是这次的核心升级:通过类似目录的路由 token,把长文本计算复杂度从 O(n²) 降到 O(n),显存占用降低 40%,推理提速 2.2 倍,首次在开源模型上实现单卡百万 token 推理。

在后训练阶段,团队将超过 10% 的集群算力投入强化学习,采用组对强化学习(GRPO)并配合多数投票,使模型在代码、数学与工具调用任务上逼近闭源水平。V3.2-Speciale 取消“思考长度惩罚”,鼓励更长的链式推理,平均输出 token 比 Gemini3Pro 多 32%,同时准确率提升 4.8 个百分点。

模型已在 GitHub 与 Hugging Face 上线,权重使用 Apache2.0 协议,可商业化。DeepSeek 表示,下一步将开源长文本 DSA 内核与 RL 训练框架,继续把“闭源优势”转化为社区基础设施。业内评论认为,若后续版本保持迭代节奏,开源阵营有望在 2026 年前实现“长文本 + 推理”的双线领先。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?