

在近日举办的技术发布会上,vLLM 团队正式宣布推出全新的 vLLM-Omni 推理框架。这款框架面向全模态(omni-modality)模型,目标是简化多模态 AI 推理流程,并为能够理解和生成多种形式内容的新一代模型提供强大支撑。与传统只能处理文本的模型不同,vLLM-Omni 能够同时应对文本、图片、音频乃至视频等多种输入和输出形式。

自从项目启动以来,vLLM 团队一直专注于为大型语言模型(LLM)提供高效的推理能力,尤其是在提升吞吐量和降低显存占用方面。如今,生成式 AI 的应用场景早已不局限于单纯的文字交互,对多模态的推理支持需求越来越迫切。正是在这样的背景下,vLLM-Omni 应运而生,成为少数首批支持全模态推理的开源解决方案之一。
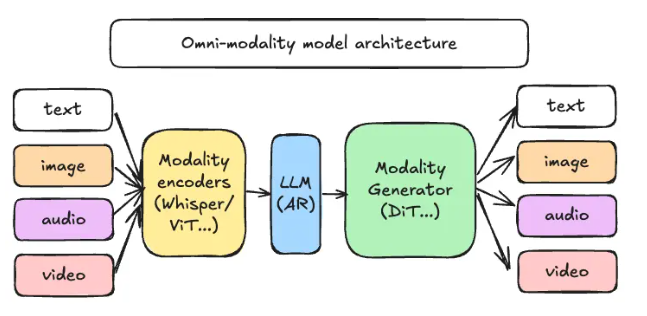
vLLM-Omni 引入了一种全新的解耦流水线架构,通过重新设计数据流,让不同环节的推理任务能够高效分配与协作。在这一架构中,推理流程主要由三大核心组件组成:模态编码器、LLM 核心以及模态生成器。模态编码器负责将各类输入数据转化为向量表示,LLM 核心处理文字生成与多轮对话,而模态生成器则用于输出图片、音频或视频的最终内容。
这种创新架构为工程团队带来了更灵活的开发体验,让他们可以在不同模块独立扩展和部署资源。这样不仅能根据业务需求灵活调整,还能让整体工作效率大幅提升。
GitHub :https://github.com/vllm-project/vllm-omni
划重点:
🌟 vLLM-Omni 是面向多模态模型的全新推理框架,可处理文本、图片、音频和视频等多种数据形式。
⚙️ 采用解耦流水线架构,提升了推理性能,并支持针对不同任务的资源优化。
📚 代码和文档已全面开源,欢迎开发者尝试、探索并进行应用创新。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?