

StepFun AI 团队近日发布了音频大语言模型 Step-Audio-R1。该模型在生成思考与答案时能更高效利用算力,针对当前音频 AI 在长链推理中准确率下滑的问题给出解决方案。研究团队强调,这并非音频模型的天生限制,而是训练中用文本替代听觉推理所造成的偏差。

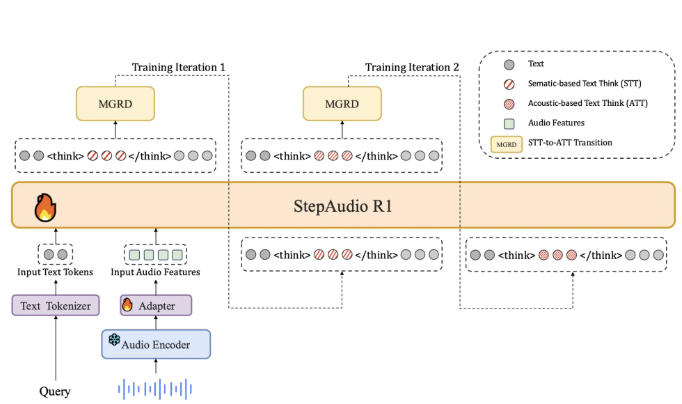
目前多数音频模型训练严重依赖文本数据,导致推理过程更像“看字”而不是“听声”。StepFun 团队将这种现象称为“文本替代推理”。为破解这一问题,Step-Audio-R1 要求模型在输出答案时必须基于真实的音频证据来思考。具体通过一种名为“模态化推理蒸馏”的训练方法实现,重点筛选并提炼与音频特征紧密相关的推理路径。
在架构方面,Step-Audio-R1 采用 Qwen2 音频编码器处理原始波形,并通过音频适配器将特征下采样至 12.5Hz。随后,Qwen2.532B 解码器读取这些音频特征并生成文本。模型生成答案时,会在特定标签中输出清晰的推理块,既优化推理结构与内容,又不影响任务的准确性。
在训练上,模型经历监督冷启动与强化学习两个阶段,混合了文本与音频任务。冷启动阶段使用了 500 万例样本,包含 1 亿个文本标记与 40 亿条音频配对数据。此阶段帮助模型学会生成对音频与文本都有效的推理,建立基础能力。
通过多轮“模态化推理蒸馏”,研究团队持续从音频问题中抽取可靠的声学证据,并用强化学习进一步打磨推理水平。Step-Audio-R1 在多项音频理解与推理基准测试上表现优异,综合成绩逼近行业领先的 Gemini3Pro。
论文:https://arxiv.org/pdf/2511.15848
划重点:
🔊 Step-Audio-R1 面向音频推理中长链准确率下滑的痛点,采用“模态化推理蒸馏”给出解决思路。
📈 模型基于 Qwen2 体系,推理时能清晰区分思考过程与最终答案,显著提升音频处理能力。
🏆 在多项基准评测中,Step-Audio-R1 的表现优于 Gemini2.5Pro,整体水平与 Gemini3Pro 接近。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?