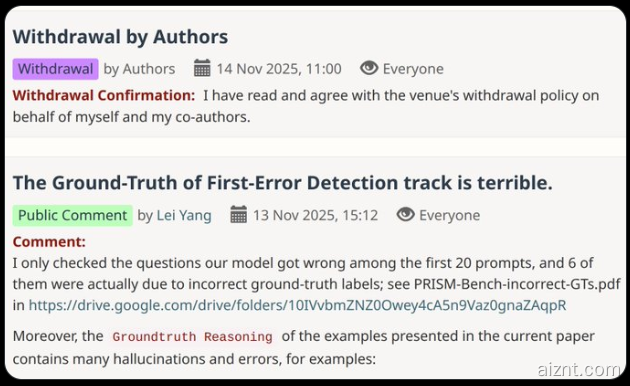


ICLR2025一审刚结束,苹果一篇宣称“小模型能压过GPT‑5”的视觉推理论文就被当场“揭短”。阶跃星辰研究员雷扬(Lei Yang)在复现中发现:官方代码竟把图片输入漏了;补上后准确率不升反降。随后他抽查了20道题,竟有6道Ground Truth标签不对——粗算整套GT错误率接近30%。

雷扬在GitHub提交issue,只得到两句回复就被关帖,遂写长文提醒审稿人。帖子迅速发酵,作者团队次日承认“数据生成流程有问题”,并火速上传修正版基准,承诺重跑实验、更新结果。此事在学界引发热议:在大模型时代,若过度依赖自动生成数据而缺少人工质检,即便是大厂也可能“翻车”。雷扬建议同行:“复现前先用小样本做个‘体检’,别让错误GT白白耗算力、熬通宵。”
参考资料:https://x.com/diyerxx/status/1994042370376032701

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?