

在当下的 AI 模型训练中,如何让合成数据既保持新鲜和多样,又不被单一调度流水线拖慢?Meta AI 研究团队给出的答案是 Matrix——一个去中心化的框架,通过把控制流和数据流打包成消息,在多个队列之间分发处理。
随着大语言模型(LLM)越来越依赖合成对话、工具调用轨迹和思维链,传统方案常用中心控制器或垂直化的特定设置,容易造成 GPU 空转、协调成本高、数据样本不够多样。Matrix 改用基于 Ray 集群的点对点智能体调度,在真实负载下实现了约 2~15 倍的令牌吞吐量提升,同时保持近似的输出质量。

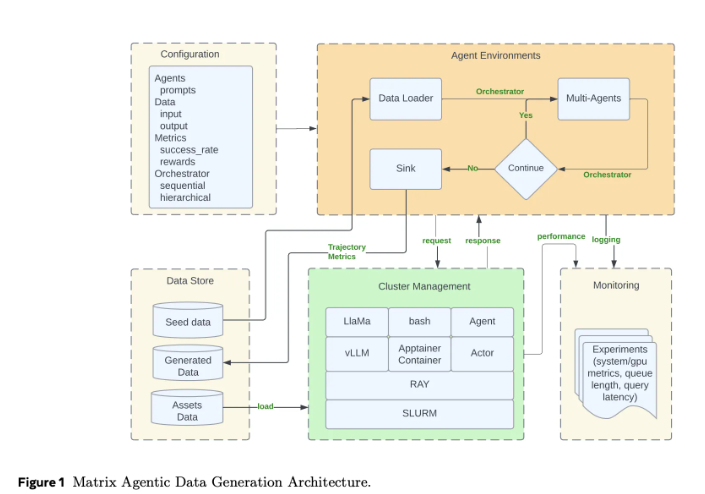
以往的智能体框架把工作流状态与控制逻辑放在中心调度器里,所有智能体和工具调用都要经过它。这种方式容易理解,但在需要同时跑成千上万条合成对话时就会卡壳。Matrix 的做法是把控制和数据序列化成一个名为“调度器”的消息对象。每个无状态智能体作为 Ray 的 actor,从分布式队列里取到该消息,执行各自的逻辑后更新状态,并把消息直接交给下一个智能体。这样既减少了不同轨迹长短带来的空等时间,出错时也能更局部地处理。
Matrix 部署在 Ray 集群上,通常通过 SLURM 启动。Ray 负责分布式智能体与队列,Hydra 用来管理角色配置、调度器类型和资源配比。框架还加入了“消息卸载”机制:当对话历史超出阈值时,把大体量内容存到 Ray 的对象存储中,在调度器里只保留对象标识符,从而节省集群带宽。
在三个案例研究中,Matrix 展示了显著性能:在 Collaborative Reasoner 的对话生成任务中,令牌吞吐量达到 2 亿,而传统方法为 0.62 亿;在 NaturalReasoning 数据集构建上,吞吐量提升 2.1 倍;在 Tau2-Bench 工具使用轨迹评估中,吞吐量提升达到 15.4 倍。更重要的是,这些提升并未牺牲结果质量,展现出高效、稳定的合成数据生成能力。
论文:https://arxiv.org/pdf/2511.21686
划重点:
🌟 去中心化的 Matrix 避开了中心调度器带来的性能瓶颈。
🚀 多项实测中,令牌吞吐量提升在 2~15 倍之间。
🔧 依托 Ray 集群的分布式特性,实现高效的合成数据生成与处理。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?