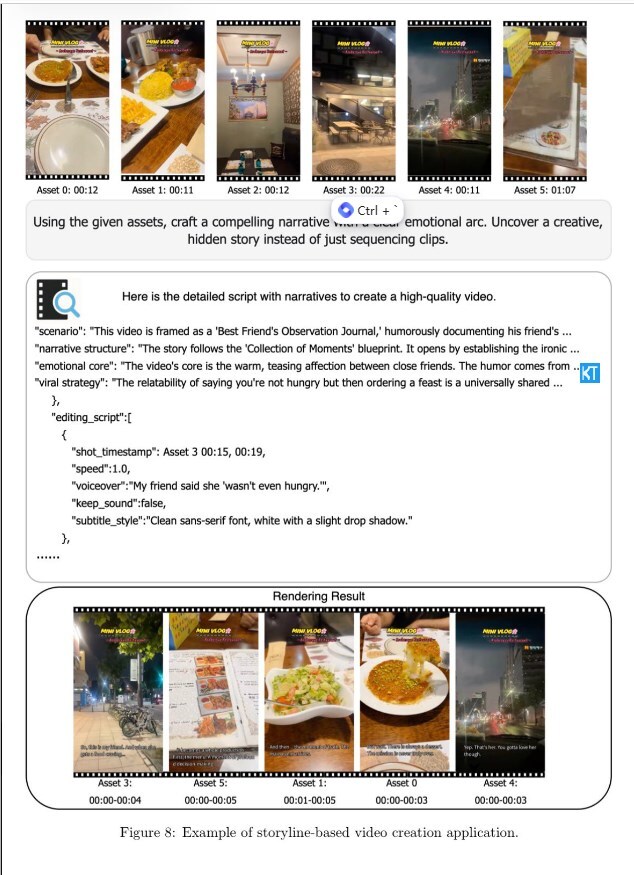


字节跳动刚刚上线其全新的多模态大语言模型 Vidi2,这是一款拥有120亿参数、重点针对视频理解的AI模型。它能处理数小时的原始素材,洞察故事线索,并依据简单提示自动生成完整的TikTok短视频或电影片段,被认为将对现有视频剪辑流程带来巨大改变。
突破:精细时空定位(STG)
Vidi2的核心优势在于视频理解能力。新模型加入了精细的时空定位(STG)模块,能够同时识别视频中的时间戳与目标对象的边界框。当给出文本查询时,Vidi2不仅会锁定对应时间段,还能在该时间范围内精准圈定具体物体的位置。
在技术细节上:
-
时空定位:模型返回“管道”(按时间索引的边界框),以一秒为粒度连续跟踪指定对象或人物,可直接用于编辑场景,例如在人群中精准追踪某个个体。
-
技术架构:Vidi2升级采用 Gemma-3 作为主干网络,并配合重构的自适应标记压缩方案,确保处理超长视频时既高效又不丢关键细节。
性能领跑:超长视频理解优势明显
在行业基准中,Vidi2表现突出。于开放式时间检索的 VUE-TR-V2基准中,其总体 IoU 达到 48.75;尤其在**超长视频(超过1小时)**的场景下,相比商业模型领先 17.5个百分点。在定位任务(VUE-STG)上,模型同样拿下 vIoU32.57 与 tIoU53.19 的最佳成绩。

从模型到产品:TikTok的“智能剪辑师”
基于 Vidi2的能力,字节跳动已打造多款自动化编辑工具,包括:高光自动提取、故事语义剪切、内容感知重构图与多视角切换,而且这些功能可在消费级设备上顺畅运行。
-
TikTok应用:相关技术已落地 TikTok的Smart Split 功能,可自动剪辑、智能重构图、添加字幕,并把长视频转化为适配TikTok的短片段。
-
AI Outline:该工具能把简单提示或热门话题生成结构化的视频标题、开场与大纲。
业内观点认为,Vidi2的发布叠加字节跳动在 **TikTok(10亿日活用户)** 的数据平台优势,为其提供了海量视频数据训练与实时反馈优化能力,这对以AI为核心的创业公司带来不小挑战。随着大型平台技术飞轮加速转动,传统AI公司可能面临更激烈的竞争。
目前 Vidi2仍处于研究阶段,官方称 Demo 即将公开。
地址:https://www.alphaxiv.org/abs/2511.19529

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?