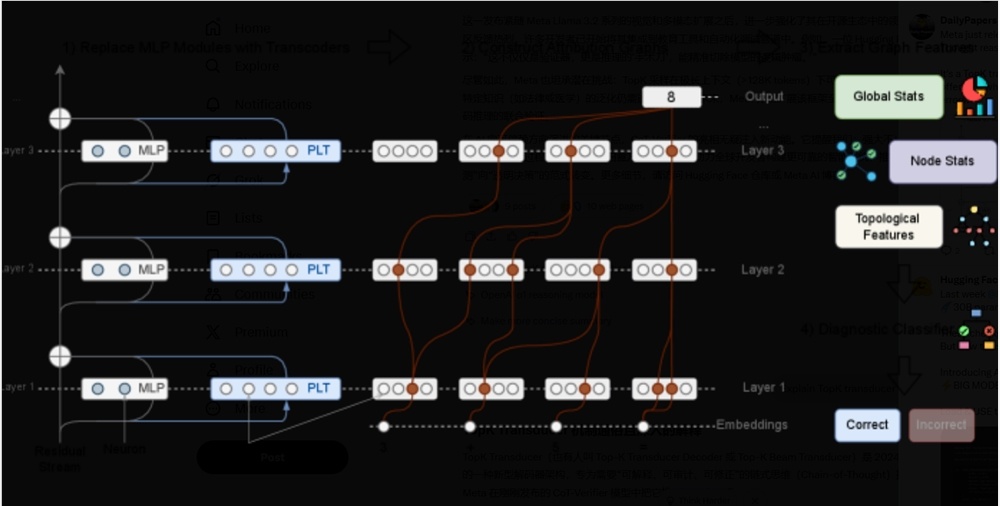


Meta AI 实验室今天在 Hugging Face 上发布了一款新型大模型,专门用于验证和优化链式思维(Chain-of-Thought,CoT)推理。该模型暂名为“CoT-Verifier”,基于 Llama 3.1 8B Instruct 架构打造,并引入 TopK 转码器(Transducer)机制,提供少见的白盒方案,帮助开发者深入定位并修复 AI 推理中的错误步骤。

目前的 CoT 验证多依赖黑盒评估,或用激活信号做灰盒分析来判断推理是否可靠。虽然有用,但很难看清失败的真正原因。为此,研究团队提出了 CRV 方法,认为各个推理步骤的归因图(也就是模型内部推理电路的运行轨迹)在结构上存在显著差别。
研究显示,正确步骤与错误步骤的归因图在结构特征上有清晰区分。这种差异为预测推理错误提供了可靠依据。团队训练了分类器来分析这些结构特征,结果证明,错误相关的结构特征具有很强的可预测性,也进一步说明直接从计算图评估推理正确性是可行的。
此外,这些结构特征在不同类型的推理任务中呈现出明显的领域特异性。也就是说,不同的推理失败对应着不同的计算模式,为后续研究指明了方向。更重要的是,研究团队基于对归因图的深入理解,进行了面向特征的定向干预,成功纠正了部分推理错误。
这项工作让我们对大模型的推理过程有了更具因果性的认识,从单纯的错误检测迈向更全面的模型理解。研究人员期待,通过细看模型的计算过程,未来能更有效地提升大语言模型的推理能力,并为更复杂的智能系统打下理论基础。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?