

Meta 与芝加哥大学、加州大学伯克利分校的研究人员联合打造了全新框架——DreamGym,专门应对用强化学习(RL)训练大型语言模型(LLM)代理时的高成本、复杂工程和反馈不稳定等痛点。DreamGym 通过在可控的模拟 RL 环境中训练代理,帮助其高效处理复杂应用。
在训练过程中,DreamGym 会根据代理的表现动态调节任务难度,让模型循序渐进地掌握并挑战更难的问题。实验结果表明,无论是完全模拟的场景,还是需要把模拟学习迁移到现实世界的任务中,DreamGym 都能显著提升 RL 训练效果。在那些可用 RL 但交互代价高昂的环境里,它甚至仅依靠合成交互数据,就能达到与主流算法相近的性能,大幅降低数据采集与环境交互成本。

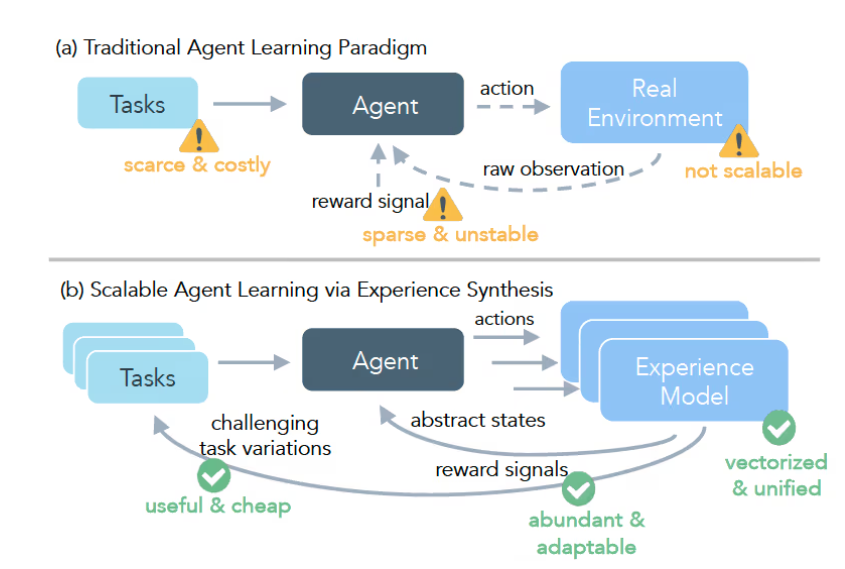
用 RL 训练 LLM 代理面临不少难点:现实应用通常需要长链条操作且回报稀疏,只有完成一系列正确步骤才会得到正反馈;此外,收集足够多样且经过验证的数据很贵,往往需要人类专家参与审核与标注。为此,DreamGym 提供了一条高效且更安全的训练路径。
DreamGym 的核心由三部分构成:第一是“基于推理的经验模型”,把目标环境的动态过程映射到文本空间,用来模拟应用环境;第二是“经验回放缓存”,充当可更新的记忆库,指导经验模型进行预测,确保合成经验的多样性;第三是“课程式任务生成器”,会依据代理的表现自动生成更新、更具挑战性的任务。三者协同运行,形成闭环系统,从而实现高效的代理训练。
研究团队在电商、具身控制以及真实网页交互等多个基准上验证了 DreamGym。结果显示,它在多类任务中整体表现更优,尤其在 WebArena 环境下,训练出的代理成功率较基线方法提升 30% 以上。借助这一方案,DreamGym 为过去难以落地的领域带来了可行的 RL 训练路径。
划重点:
🌟 DreamGym 通过模拟环境训练 AI 代理,明显降低了 RL 训练的成本与风险。
🚀 框架会动态调整任务难度,帮助代理循序渐进地攻克更复杂的问题。
💡 实验结果显示,DreamGym 在多种应用场景下整体优于传统方法。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?