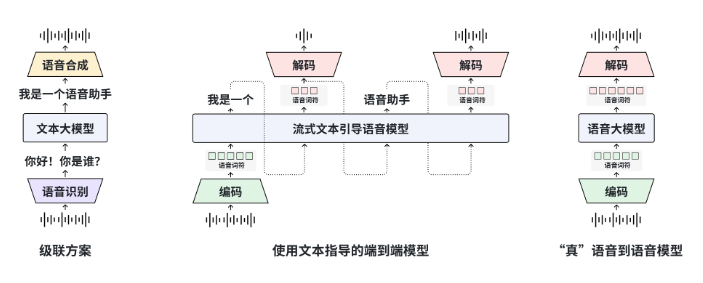


复旦大学MOSS团队发布了全新MOSS-Speech,首度实现端到端的语音到语音对话;目前已在Hugging Face提供在线演示,权重与源码同步开放。MOSS-Speech采用“分层拆解”思路:保留并冻结原MOSS文本模型参数,额外加入语音理解、语义对齐和神经声码器三层,能一次完成语音问答、情感模仿与笑声生成,无需传统的ASR→LLM→TTS三级流水线。

测评结果表明,MOSS-Speech在ZeroSpeech2025无文本语音赛道上,将WER降低到4.1%,情感识别准确率达到91.2%,整体超过Meta的SpeechGPT与Google AudioLM;中文口语主观MOS评分为4.6,逼近真人录音的4.8。项目同时提供48kHz超采样版本和16kHz轻量版本,其中轻量版可在单张RTX4090上实现实时推理,延迟<300ms,适合移动端落地。

团队表示,后续会推出并开源“语音控制版”MOSS-Speech-Ctrl,可用口令动态调节语速、音色和情感强度,预计2026年Q1发布。MOSS-Speech已提供商用授权,开发者可在GitHub获取训练与微调脚本,在本地完成私有声音克隆与角色化配音。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?