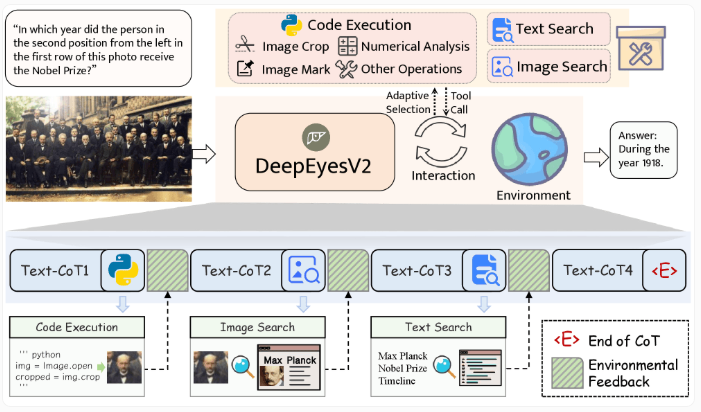


近期,国内研究团队发布了一款名为 DeepEyesV2 的多模态 AI,它能看图、跑代码,还会上网检索。不同于只依赖训练期记住的知识,DeepEyesV2 通过巧用外部工具表现亮眼,很多场合下还能压过体量更大的模型。
在最初的实验中,团队发现单靠强化学习,很难让模型稳定地用好工具完成多模态任务。起初,模型会尝试写 Python 来做图像分析,但常常产出有误的代码片段;随着训练推进,它甚至开始直接不使用工具了。

为了解决这个问题,研究者设计了两段式训练流程:第一阶段,让模型学会把图像理解与工具调用紧密结合;第二阶段,再用强化学习对这些行为进行打磨与优化。借助业界领先模型生成的高质量示例,团队保证了工具使用路径的准确、清晰。
DeepEyesV2 围绕三类工具来处理多模态任务:代码执行用于图像处理与数值计算;图像搜索用来找相似内容;文本搜索补足图中不可见的背景信息。模型通过整合图像操作、Python 执行以及图像/文本检索,可根据不同提问灵活应对。
为评估该方案,团队构建了 RealX-Bench 基准,检验模型在视觉理解、网络检索与推理上的协同能力。结果显示,即便是表现最强的商用闭源模型,准确率也只有 46%,而人类可达 70%。在需要三项能力同时配合的任务上,现有模型的短板更为明显。

在多项基准上,DeepEyesV2 表现不俗:数学推理准确率达 52.7%,搜索驱动任务达 63.7%。这说明,通过精心设计的工具链,小模型也能弥补自身限制。
DeepEyesV2 已在 Hugging Face 与 GitHub 开源,采用 Apache License 2.0,可用于商业场景,继续推动多模态 AI 的落地与进步。
论文:https://arxiv.org/abs/2511.05271
划重点:
🌟 借助智能工具,DeepEyesV2 在多模态任务上实现跃升,部分场景超越更大模型。
🔧 采用两阶段训练,将图像理解与工具调用深度结合。
📈 多项基准表现亮眼,展示小模型的上限仍可被拓展。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?