

近日,摩尔线程的 AI 研究团队在国际顶级学术会议 AAAI2026上公布了其最新进展,推出名为 URPO(统一奖励与策略优化)的创新框架。该技术旨在让大语言模型的训练流程更简洁,并突破性能瓶颈,为 AI 领域开辟新的技术路线。
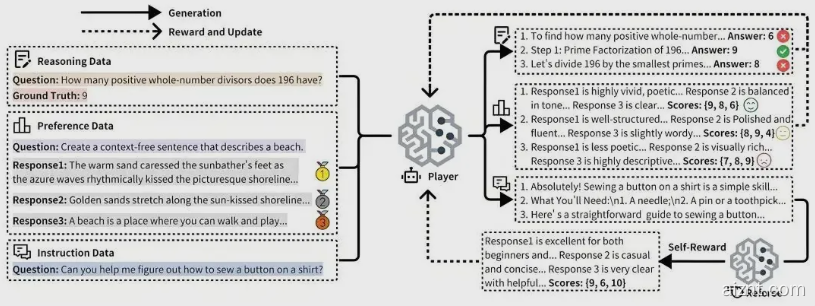
在题为《URPO: A Unified Reward & Policy Optimization Framework for Large Language Models》的论文中,研究团队对传统“大模型训练”的做法进行了重构。URPO 的核心亮点,是把“指令遵循”和“奖励评估”两种角色合并到同一个模型里,在训练阶段同步优化。也就是说,模型既能理解指令,又能自行评分,从而提升训练效率与效果。

URPO 框架在三项关键技术上突破了现有难题。第一,数据格式统一:团队将偏好数据、可验证推理数据与开放式指令数据,转化为适配 GRPO 训练的统一信号。第二,自我奖励闭环:模型在生成多份候选回答后能自评打分,并把结果作为 GRPO 的奖励信号,形成高效的自我改进循环。第三,协同进化机制:通过三类数据的混合训练,让模型的生成能力与评判能力相互促进、同步增强。
实验结果表明,基于 Qwen2.5-7B 的 URPO 框架,在多项指标上超越了依赖独立奖励模型的传统基线。例如,在 AlpacaEval 指令跟随榜单上,成绩提升至 44.84;综合推理能力测试的平均分从 32.66 提升到 35.66。同时,在 RewardBench 奖励模型评测中,URPO 取得 85.15 的高分,优于专用奖励模型的 83.55,充分展现了该框架的优势。
值得关注的是,摩尔线程已在其自研计算卡上高效落地 URPO,并完成与主流强化学习框架 VERL 的深度适配。这一进展不仅彰显了摩尔线程在大模型训练方向的领先实力,也为未来 AI 的发展指明了新方向。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?