

近日,微博旗下人工智能团队开源了 VibeThinker-1.5B,这是一款拥有15亿参数的语言模型(LLM)。该模型在阿里巴巴的 Qwen2.5-Math-1.5B 基础上做了精调,现已在 Hugging Face、GitHub 和 ModelScope 免费开放,研究人员与企业开发者都可使用,商业场景也不受限,遵循 MIT 许可协议。

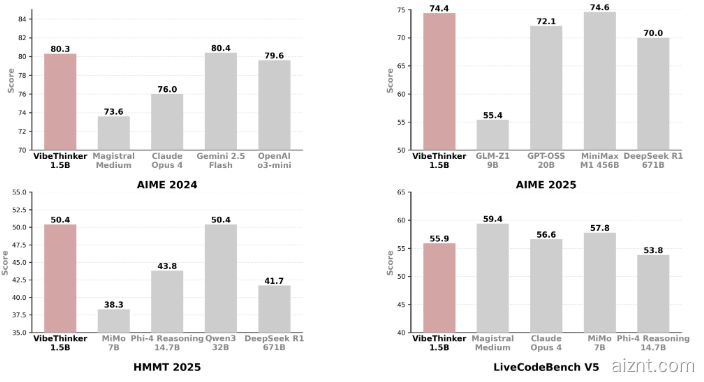
虽然 VibeThinker-1.5B 体量不大,但在数学与编程任务上表现亮眼,推理能力达到行业前列,甚至超过参数高达6710亿的竞品 DeepSeek R1。它还能与 Mistral AI 的 Magistral Medium、Anthropic 的 Claude Opus4 以及 OpenAI 的 gpt-oss-20B Medium 等多款大型模型对标,却只需更低的基础设施和投入成本。
更关键的是,VibeThinker-1.5B 的后期训练仅花费约7800美元,远低于同类或更大模型动辄数十万甚至上百万美元的预算。LLM 的训练一般分两步:先做预训练,用海量文本学习语言规律与通识;再进行后期训练,借助更小但更优的数据,让模型更会助人、会推理,并与人类期望对齐。

VibeThinker-1.5B 采用名为“谱 – 信号原则”(Spectrum-to-Signal Principle,SSP)的训练框架,将监督微调与强化学习分成两个阶段:第一阶段强调多样性,第二阶段通过强化学习优化最优路径,让小模型也能高效探索推理空间,从而实现信号放大。
在多项评测中,VibeThinker-1.5B 的成绩超过不少大型开源与商业模型。其开源发布打破了“模型越大越好、算力越多越强”的固有观念,证明小模型在特定任务上同样能有不俗表现。
huggingface:https://huggingface.co/WeiboAI/VibeThinker-1.5B
划重点:
📊 VibeThinker-1.5B 是微博发布的15亿参数开源模型,表现强劲,部分场景可比肩甚至超越大模型。
💰 后期训练成本约7800美元,费用远低于同类模型的动辄数十万。
🔍 采用“谱 – 信号原则”训练框架,让小模型也能高效推理,提升小模型的竞争力。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?