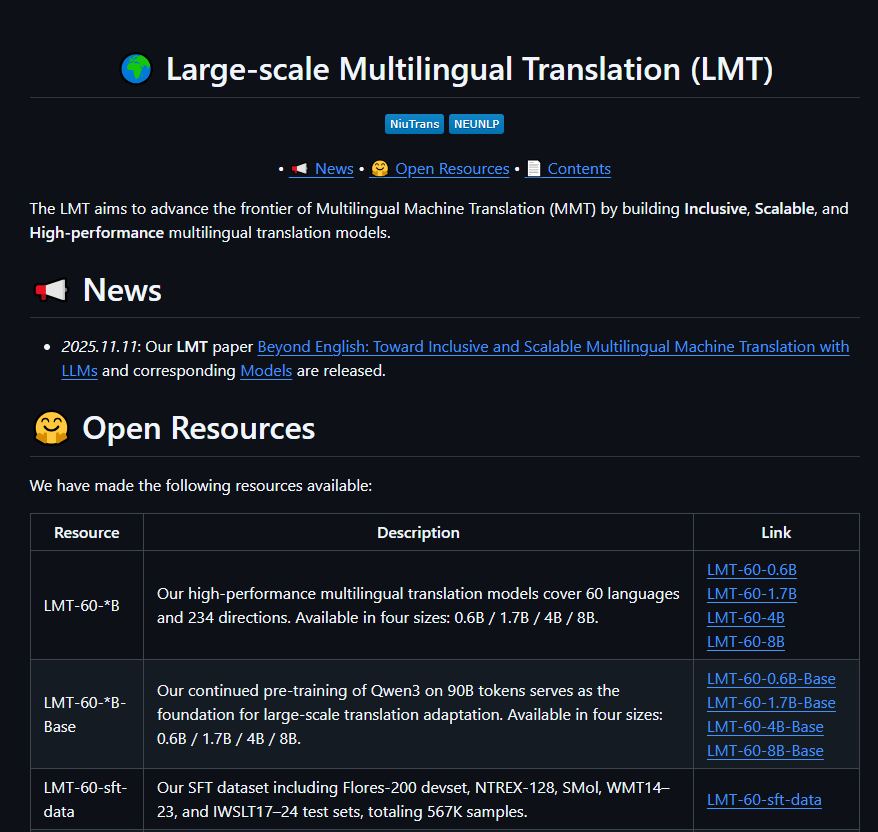


中国AI翻译再上台阶。东北大学“小牛翻译”团队近日开源其最新多语言大模型——NiuTrans.LMT(Large-scale Multilingual Translation),一次性打通60种语言、234个翻译方向。以中文与英文为双核心打造全球沟通桥梁,同时在藏语、阿姆哈拉语等29种低资源语言上取得明显提升,为语言公平迈出关键一步。

双枢纽设计,告别“唯英语论”
不同于很多以英语为唯一中转的翻译模型,NiuTrans.LMT采用“中文-英文”双中心方案,支持中文↔58种语言、英文↔59种语言的高质量直译,避免“中文→英文→小语种”的二次偏差。该设计更利好“一带一路”沿线国家与中文用户的直接交流,推动跨文化沟通去中介化。

三层语言梯度,平衡效率与公平
模型将语言按资源水平细分为三档:
13种高资源语言(如法语、阿拉伯语、西班牙语):翻译顺畅度接近人工;
18种中资源语言(如印地语、芬兰语):专业术语与语法结构表现稳定、准确;
29种低资源语言(含藏语、斯瓦希里语、孟加拉语等):借助数据增强与迁移学习,从“难以翻译”迈向“可用翻译”。
两步训练,FLORES-200成绩拔尖
NiuTrans.LMT在权威多语言评测FLORES-200上表现突出,位居开源模型前列。其优势来自创新的两阶段训练流程:
继续预训练(CPT):在900亿tokens的多语言语料上均衡学习,保障小语种不被忽视;
监督微调(SFT):融合FLORES-200、WMT等高质量平行数据(56.7万条样本,覆盖117个方向),进一步提升准确度与风格一致性。
四个参数规模全开源,科研到落地全场景覆盖
面向不同使用场景,团队同步开源0.6B、1.7B、4B、8B四个参数规格,均可在GitHub与Hugging Face免费下载。轻量模型可用消费级GPU运行,适合移动端与本地部署;8B版本面向企业级高精度翻译,支持API接入与私有化部署。
有观点认为,NiuTrans.LMT的发布不仅是技术进展,更是对“语言多样性”的实际守护。当AI能准确翻译藏语诗歌、非洲谚语或北欧古语,技术才更有人文温度。东北大学的开源行动,正为构建无语言壁垒的数字世界打下基础。
项目地址:https://github.com/NiuTrans/LMT

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?