

Meta 的 AI 研究团队携手新加坡国立大学,提出了一套名为“SPICE(自我对弈环境中的自我提升)”的全新强化学习框架。它让两个智能体彼此博弈,自动生成持续升级的挑战,使系统在无人工干预的情况下不断进步。虽然目前仍处于概念验证阶段,但这一思路有望为能随环境动态适应的 AI 奠定基础,让模型在真实世界的不确定性面前更稳健。

所谓自我提升,是指让 AI 通过与环境交互来强化能力。传统做法多依赖人工设计的题库和奖励规则,扩展起来很吃力。自我对弈让模型靠竞争变强,但用于语言模型时会遇到障碍:问题与答案中的事实错误可能相互叠加,容易出现“幻觉”;而且当出题者和解题者共享同一知识库时,难以产出真正新的挑战,容易陷入重复模式。
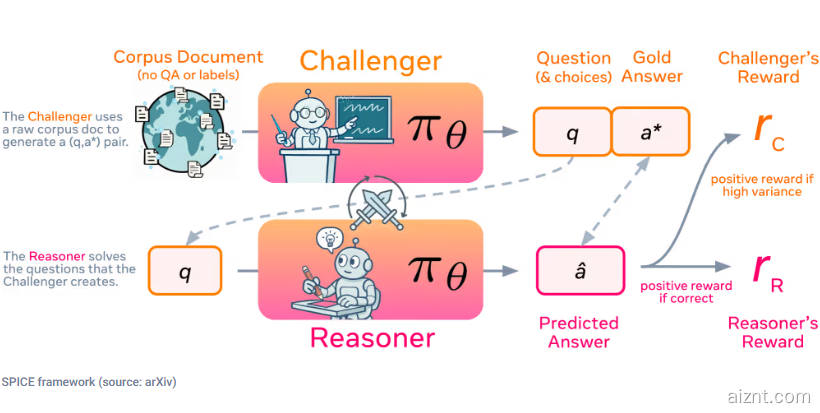
SPICE 引入了别样的自我对弈设计:同一模型分别担任两种角色——“挑战者”从海量文档中提取并构造高难度问题,“推理者”在不访问原始资料的前提下尝试作答。通过这种信息不对称的设置,解题方无法直接使用出题方的材料,因而有效降低了错误和偏差。

这种博弈过程相当于自动化的“课程设计”:挑战者因提出多样、恰好卡在推理者能力边缘的题目而得到奖励;推理者则凭正确作答拿到奖励。双向激励让两方同步进步,不断挖掘并攻克新难点。由于系统直接使用原始文档而不是固定的问答对,它能产出多种任务形式,跨领域适用,突破了以往方法的场景限制。
研究团队在多个基础模型上进行评估,结果显示 SPICE 在数学与通用推理任务上表现亮眼,优于其他基线方法。这说明基于语料库的自我对弈所学到的推理能力具备良好迁移性,有望开启自我提升推理的新阶段。
论文:https://arxiv.org/abs/2510.24684
划重点:
✅ SPICE 以自我对弈为核心,让 AI 在无人工标注的条件下持续增强推理。
✅ 挑战者和推理者分工明确,制造信息不对称,降低出错概率。
✅ 多模型评测中成绩突出,说明 SPICE 兼具通用性与实效。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?