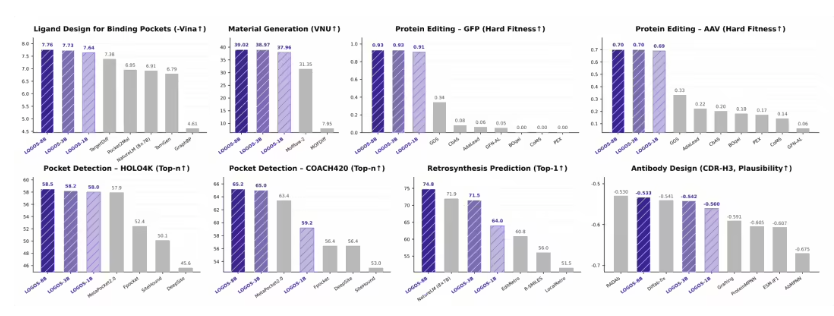


阿里 ATH-Token Foundry 携手中国人民大学高瓴人工智能学院,今天正式对外开源了首个建立在统一科学语法之上的多领域科学生成基础模型 LOGOS。在六类具有代表性的科学任务中,这一模型依靠纯序列建模方式,整体上达到了甚至超过传统领域专用方法的效果。

更值得一提的是,这款模型在参数使用效率方面表现非常突出。只有 1B 参数的 LOGOS-1B,在多个关键任务上的成绩,已经超过参数规模达到 8×7B 的微软 NatureLM 语言模型。
首次用统一科学语法整合异构对象
LOGOS 搭建了一个覆盖生物大分子、化学实体以及界面互作等 7 类模态、总量达到 44.87B tokens 的大规模预训练语料库。借助共享词表设计,它把蛋白质、小分子等原本不同类型的对象,统一编码成离散 Token 序列。
这种特别的科学语法设计,使不同科学对象能够在同一个生成空间里,被大模型通过自回归方式统一理解。它还提出了一种类似“文字描述”的方法,不需要输入复杂的 3D 坐标,只通过序列预测,就能建立起对复杂空间互作规律的理解。

打通预训练与实际应用之间的断层
在传统科研流程里,只要切换一个研究环节,往往就要换一套模型,这也让模型真正落地时需要大量微调。LOGOS 则做到了形式和目标的高度统一,其预训练数据的序列形式,与下游任务的输入输出形式完全一致。
这样的高度对齐,明显缩小了预训练和下游应用之间的差距,不用复杂适配层也能直接释放生成能力。当前,阿里已经将这一大模型的权重、推理代码和技术报告全部完整开源。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?