

人工智能在科研领域的落地,正进入一个全新的阶段。6月18日,阿里 ATH-Token Foundry 携手中国人民大学高瓴人工智能学院,正式开源了一款名为
一直以来,不同学科之间都存在明显的“语言隔阂”。蛋白质、小分子以及复杂材料,在AI系统中通常属于结构差异很大的独立数据类型。为了让这些科学对象能够被统一理解,以往研究通常要依赖复杂的3D坐标信息,或专门构建几何神经网络,不但计算代价很高,而且通用能力有限,换一个任务往往就要重新搭建方案。

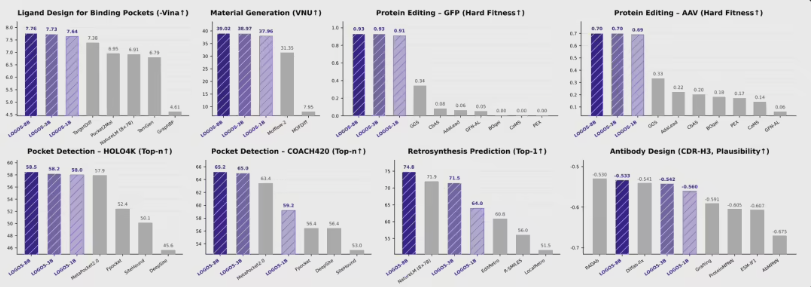
LOGOS 的关键突破,就在于打通了这层壁垒。它构建了一套共享词表,把蛋白质、抗体、小分子和 MOF 材料等不同类型的对象,统一编码成离散 Token 序列。也就是说,模型不再高度依赖昂贵的3D空间信息,而是像“读文本”一样,通过序列预测直接学习复杂的3D空间相互作用规律。这样的“科学语法”,让不同学科的数据第一次能够在底层实现知识互通。

在参数效率方面,LOGOS 的表现同样十分亮眼。LOGOS-1B 版本仅凭微软 NatureLM 1/56 的参数规模,就在多项具有代表性的科学任务中实现了反超。与此同时,LOGOS 还解决了预训练和下游任务之间常见的“目标偏移”问题,让模型无需复杂微调和额外适配,就能直接释放生成能力,显著降低科研人员的使用门槛。
目前,LOGOS 已建立起覆盖7类模态、总量达到44.87B tokens 的超大规模预训练语料库。项目团队也已经将模型权重、推理代码以及完整技术报告全部开源,开发者可以通过
这项突破不仅为科研自动化提供了更强有力的技术引擎,也为未来多模态科学大模型的发展提供了新的范式。随着 LOGOS 正式开源,科学界的“语言体系”或许将迈向更统一、更高效的新阶段。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?