全球开源大模型生态如今迎来一次架构层面的重要突破。6月3日,谷歌正式推出全新统一多模态模型Gemma412B。这款模型最大的亮点,是完全去掉了传统多模态模型中几乎必备的“编码器”模块,让它在消费级硬件上的本地部署和推理效率实现了明显提升。
在以往的多模态架构里,模型往往要借助独立的视觉编码器和音频编码器,把图像、声音信号转换成能和文本Token对应的维度,这样一来,模型体积更大,计算过程也更复杂。而Gemma412B选择了另一种思路,使用轻量化嵌入层直接处理视觉输入,只需要一次矩阵乘法、位置嵌入以及归一化步骤就能完成转换;与此同时,音频信号也会被直接映射到文本Token所在的维度空间中。这样的“无编码器”精简方案,不但减少了大量计算环节,也让整个模型更加轻便。

正因为底层架构做了大幅精简,这款拥有120亿参数的高性能模型,被成功控制在消费级硬件可承受的运行范围内。无论是开发者还是普通用户,只要拥有16GB显存或统一内存,就可以在高性能笔记本上直接完成本地部署并顺畅运行。这也意味着,用户不必再依赖价格高昂的云端算力,就能够离线处理复杂的视觉与音频任务。
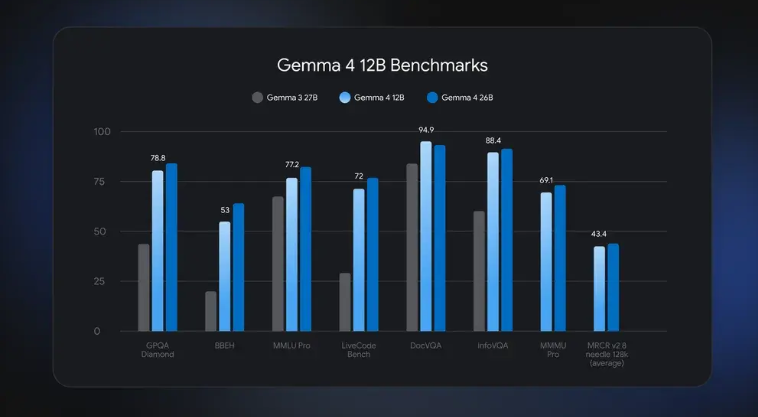
从实际性能来看,Gemma412B在多步推理和代理工作流(Agent)方面的能力,已经接近谷歌体量更大的26B MoE模型。为了继续提升性能表现,这款模型还加入了多Token预测(MTP)技术,可以一次同时预测多个Token,从而进一步加快端侧推理的响应速度。
目前,Gemma412B已经在 Apache2.0 许可证下正式开源,模型权重也已同步上线。新模型同时获得了主流开发生态的广泛支持,不仅可以无缝兼容 Ollama、LM Studio、MLX、SGLang 和 vLLM 等多种推理框架,谷歌自家的 AI Edge Gallery 也第一时间给出了端侧部署包。对于企业级生产场景,开发者还能够借助谷歌云相关工具进行大规模集群部署。随着 Gemma4 系列模型累计下载量突破1.5亿次,这套全新的架构显然会在开源开发者社区掀起新一轮技术热潮。




















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?