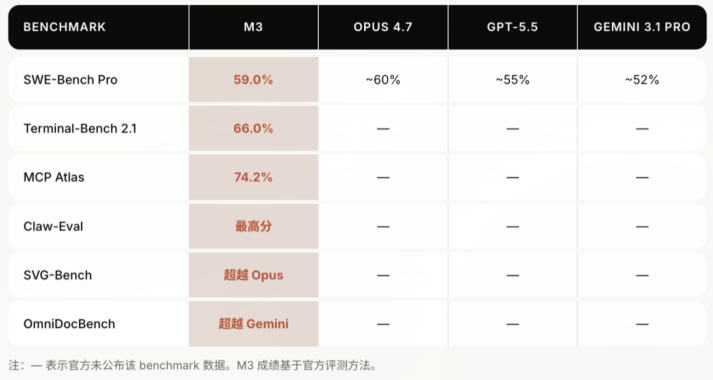


大模型领域再次起了新动静。AI创业公司MiniMax最近正式推出了新一代旗舰大模型M3。从技术报告公开的多项基准测试(Benchmark)结果来看,这款模型的表现确实很抢眼:在被普遍认为更贴近真实软件工程环境的测试中,M3拿到了59%的优秀成绩,不但超过了GPT-5.5,还已经非常接近Opus4.7。另外,它还支持百万级上下文处理,并且具备原生多模态能力。不过,和这些强势技术数据形成强烈反差的是,M3发布之后在开发者社区里引发了不小争议,尤其在中文社区,负面声音更是非常集中。
业内争议的第一个关键点,在于评测结果背后是否足够透明。根据技术细节说明,M3在 Coding(代码)能力相关测试中,采用了竞品Claude Code作为评测脚手架。虽然在当前行业里,借助现成工具链来跑智能体(Agent)评测并不罕见,但MiniMax使用别人的框架来测试自家模型,再直接拿结果与对方同台比较并对外宣传,这种做法让不少程序员觉得“并不够坦率”。对于普通用户来说,也很难判断这些高分里,到底多少来自模型本身,多少又来自脚手架带来的额外加成。

另外,关于“开源”这件事是否拿出了足够诚意,也让开源社区感到疑惑。和其他厂商推出开源模型时的做法不同,MiniMax这次不仅没有公布M3的参数规模,也没有同步开放模型“权重”,只是表示会在发布后的10天内开源,目前外界只能通过API使用。由于开源社区一直看重“可复现、可验证”,这种先打出开源口号、却暂时不给权重、让大家无法在本地独立验证模型真实情况的方式,虽然从商业角度不难理解,但确实伤到了很多重视务实和透明的开发者。

而最让长期深度用户觉得“被背后捅了一刀”的,则是计费规则(Coding Plan)在没有预告的情况下被调整。此前,MiniMax因为采用按请求次数限速、但不设置月度Token总量上限的方式,被不少人认为是“量大够用”。但随着M3上线,官方也同步推出了新的Token Plan,把规则改成了按总量计费。虽然官方表示Plus套餐的Token价格依然很划算,但在百万上下文这种重度使用场景里,单次调用往往会消耗大量Token,新规则也就意味着套餐额度可能很快被用完,因此引来了老用户的集中不满。
如果先不看这些运营层面的争议,M3在底层架构上的创新其实还是有不少看点。它自研了一套名为MSA(MiniMax Sparse Attention)的稀疏注意力机制,通过对KV(Key-Value)进行高精度分块和稀疏化处理,突破了传统Transformer在长上下文计算时计算量迅速膨胀的问题。在底层算子设计上,这个模型还提出了新的计算聚合方式,让内存访问更加连续,速度相比开源的Flash-Sparse-Attention提升了4倍以上。这也让M3在百万上下文条件下的前向传播和解码速度分别提高了9倍和15倍,单Token计算量也下降到了上一代的一半。
单从技术路线来观察,M3在长上下文、多模态以及智能体能力上的整体均衡性,在国内厂商中仍然算比较突出的。不过,这次因为发布方式和运营策略上的一连串争议操作,技术本身的亮点反而被社区质疑声盖过去了。市场对M3持续关注,同时又出现明显情绪反弹,这说明开发者对这款产品其实依旧有期待。至于MiniMax能不能重新赢回社区信任,或许还要等10天后模型权重正式公开、接受独立评测之后,才会有更清晰的答案。

















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?