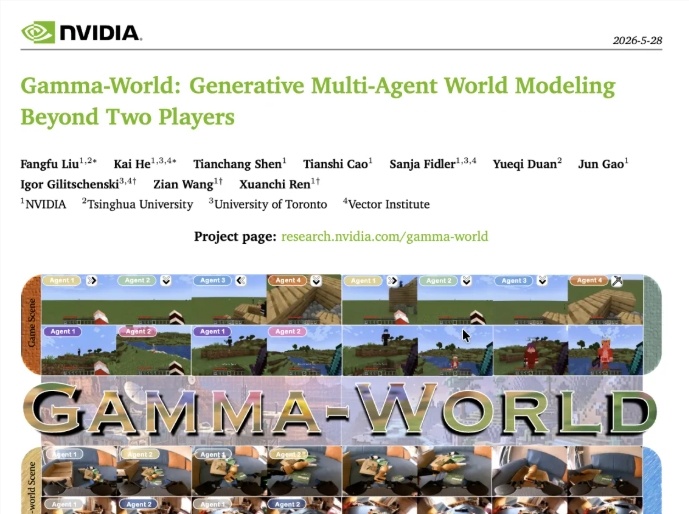


视频世界模型正在经历一场从单人视角走向多人协作的底层升级。过去的视频世界模型大多基于单智能体设定,在面对多个玩家同时在同一虚拟世界中操作、彼此观察的复杂环境时,往往难以胜任。为了解决这一架构难题,英伟达联合清华大学、多伦多大学以及 Vector Institute,正式推出了名为 Gamma-World(γ-World)的全新多智能体世界模型方案。
多智能体世界建模最大的挑战,在于要同时保证时间、跨视角和交互三方面的一致性。此前的研究例如 Solaris,虽然在双人协作方面取得了一定成果,但也暴露出两项关键问题:身份编码会破坏置换对称性,全连接注意力机制又会让计算量随着人数增加呈平方级上升,因此很难真正扩展到更多智能体场景。

针对这些结构上的不足,Gamma-World 从底层模块开始进行了全面重构。首先,团队提出了“正单纯形旋转智能体编码(Simplex Rotary Agent Encoding)”。这一方法把所有玩家映射到几何空间中的正单纯形顶点上,让每位玩家之间天然保持等距,地位也完全对等。由于这种设计不依赖可学习参数,并且通过随机分配坐标,模型无需调整原有架构,就能实现“用双人数据训练,直接适配四人场景”的强泛化能力。
另外,为了突破算力和吞吐上的限制,Gamma-World 还加入了“稀疏枢纽注意力机制(Sparse Hub Attention)”。这套设计不再采用传统的两两直接通信方式,而是通过一组可学习的枢纽 Token 充当共享世界状态的压缩中转节点,从而把计算成本降低到线性复杂度。在独立缓存技术的配合下,系统最终实现了每秒24帧(24FPS)的实时动作响应推演能力。
在训练方法上,项目使用了三阶段师生蒸馏策略,通过双向教师模型去指导因果学生模型,顺利把原本多步采样压缩到了4步采样。这一方案不仅保证了动作控制能力,也进一步减轻了自回归推演过程中的误差累积问题。
实验结果表明,在多人 Minecraft 虚拟环境中的记忆、建造等五类核心场景测试里,Gamma-World 相较当前顶尖模型实现了全面领先,衡量视频质量的 FVD 指标平均下降超过40%。与此同时,这一框架也已经成功迁移到真实双臂机器人的协作任务中,充分证明了其在不同场景下的通用能力。这不仅意味着多智能体仿真水平进一步提升,未来还有望为多臂医疗协同、工厂多机器人调度以及自动驾驶等物理 AI 应用,提供全新的大规模模拟生成基础能力。

















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?