

4月3日清晨,Google DeepMind 发布了全新的开源模型家族

全线覆盖:从手机端到工作站的“四大版本”
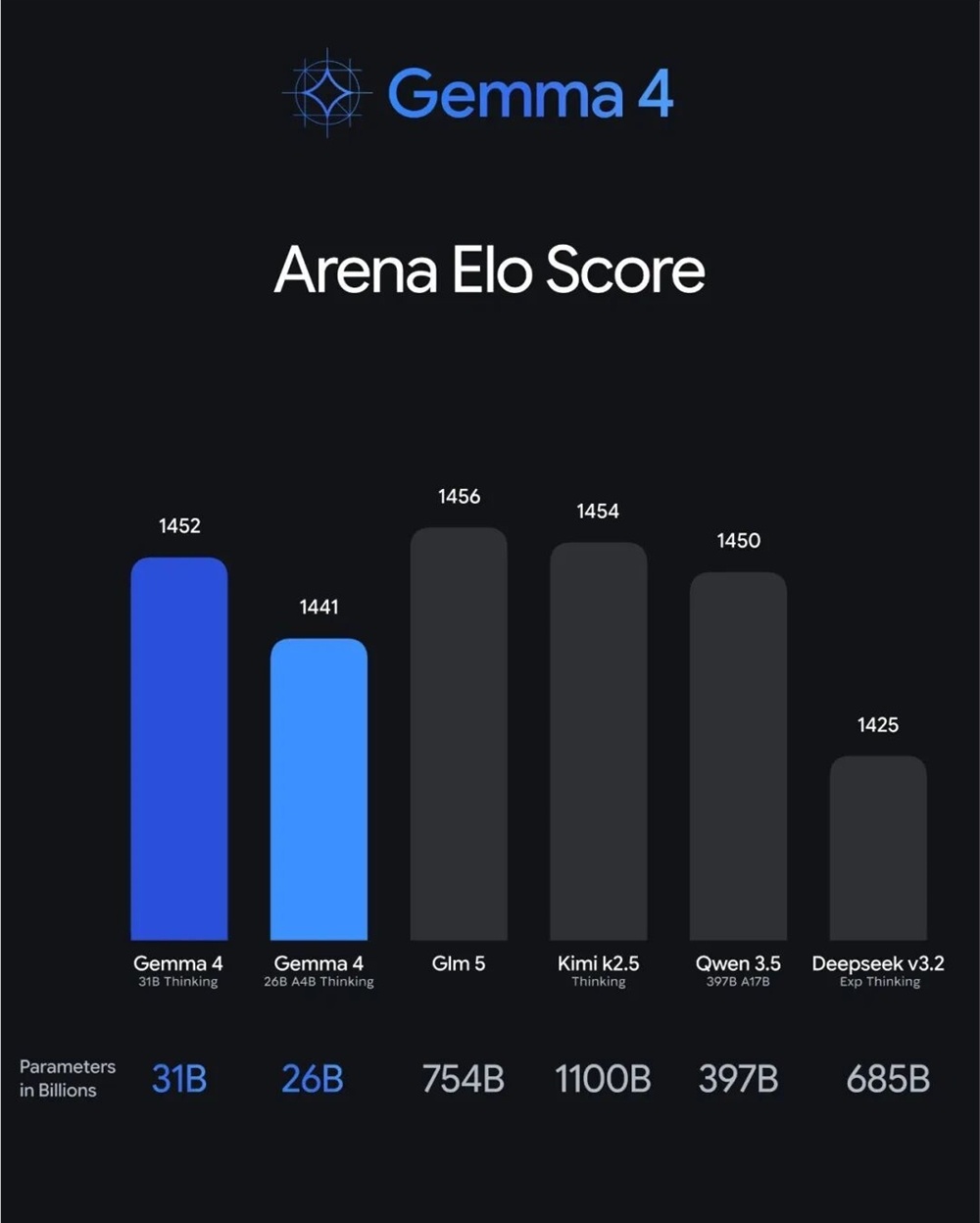
31B Dense(旗舰版):310亿全激活参数,支持 256K 超长上下文。在 Arena AI 开源榜上位居第三,未量化也能用单张 H100 跑通。
26B A4B MoE(性价比之王):采用混合专家架构,总参数 252 亿,激活仅 38 亿。推理速度接近 4B 体量,但效果大幅优于同级产品,当前排名第六。
E4B & E2B(端侧精英):面向手机与嵌入式设备深度优化。借助 Per-Layer Embeddings 技术,有效参数分别压缩至 45 亿与 23 亿,其中 E2B 在部分设备上内存占用可低至 1.5GB 以下。

性能猛进:代码与数学能力实现跨代提升
对比上一代 Gemma327B,
数学竞赛:AIME2026 成绩从 20.8% 拉升至 89.2%。
编程能力:Codeforces ELO 从 110 增至 2150;在 LiveCodeBench 上由 29.1% 提升到 80.0%,跻身开源编程助手的第一梯队。
综合推理:研究生级科学问答(GPQA Diamond)从 42.4% 接近翻倍至 84.3%。
多语言能力:原生支持 140+ 语言,MMMLU 得分达 88.4%。

核心亮点:内置“思考模式”与 Agent 基因
Thinking Mode:提供可切换的“思考模式”,在给出答案前先进行内部推演,多步骤规划类任务更稳、更准。
原生 Agent 支持:支持函数调用与结构化 JSON 输出。谷歌同步推出开源 Agent 开发工具包(ADK),让端侧模型也能便捷打造“智能体”。
深度多模态:全系支持图像与视频输入,小型号还内置音频编码器,覆盖语音识别与翻译。
行业观察:开源赛道的“权力重组”
过去一年,国内开源模型(如 DeepSeek、Qwen、GLM 等)迭代飞快,谷歌在开源圈的存在感一度下降。
结语:当大厂拿出“诚意”
从自定义协议转向 Apache2.0,谷歌用行动回应了开源的诚意。当 31B 规模的模型能逼近闭源旗舰表现,并可在消费级显卡甚至手机上流畅运行时,全球开发者的创作边界将再被拉宽。

















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?