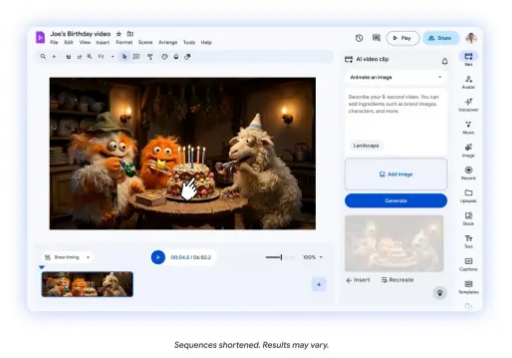


4月2日,谷歌宣布其企业级视频创作应用 Vids 迎来重要升级:通过集成 Veo3.1 视频生成模型并结合自然语言交互,让产品从静态生成迈向可“指令操控”的动态创作。此次更新的重点,是给 AI 虚拟形象带来更强的互动能力。用户只需输入简单的文字提示,就能让角色在场景中与产品、道具或设备进行指定动作互动,同时在生成的动态画面中保持角色外观的一致性。
同时,Vids 的多模态能力进一步加强。在近期接入

为打通从制作到发布的流程闭环,
与此同时,AI 领域的竞争持续升温。微软同日推出 MAI 系列三款基础模型,覆盖25种语言的语音转写、音频生成与视频生成能力,意在以更低成本门槛挑战谷歌与 OpenAI 的市场优势。
自2024年推出 Vids 以来,谷歌快速迭代了3D 卡通形象与多语言支持。这种基于提示词的精细化操控,意味着 AI 视频工具正从简单的内容生成,迈向更专业的“自动化导演”阶段,并将进一步重塑企业内容生产的成本结构与创意边界。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?