

中国大模型在全模态交互赛道,正完成从“跟跑”到“领跑”的跃迁。
3月30日,

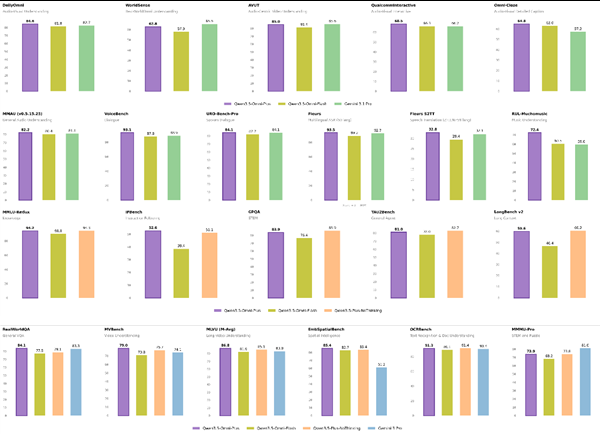
全能战力:215 项夺魁,硬核超越 Gemini
在衡量大模型综合能力的关键维度上,
SOTA 横扫: 在覆盖音视频理解、识别与交互的 215 项评测中,均取得 SOTA(表现最佳)成绩。
同台领先: 在 DailyOmni、QualcommInteractive 等聚焦视听交互的测试上,分数显著压过 Google 的 Gemini-3.1Pro。
强抗噪音: 在嘈杂场景的 WenetSpeech 测试中,识别准确率极高,错误率显著低于对手。
交互新纪元:支持 113 种语言,“动嘴就能编程”
多语通晓: 能覆盖 113 种语言与方言识别,连毛利语、海南方言等小语种也能精准识别。
Vibe Coding 升级: 音视频编程全面进化。打开摄像头,对着草图口述需求,模型即可产出包含复杂 UI 的产品原型,实现“所说即所得”。
生产力加速:10 小时音频也能长程理解
面向专业场景,模型带来更强的结构化处理能力:
视频细粒度解析: 可对画面主体、人物关系与情绪变化进行深度拆解,颗粒度更细。
一键切片: 支持超 10 小时音频输入,自动完成视频章节划分与时间戳标注,大幅提升内容创作效率。
普惠生态:价格仅为 Gemini 的十分之一
成本更低: 每百万 Tokens 的输入成本低于 0.8 元,约为 Gemini-3.1Pro 的十分之一。
行业领先: 目前
结语:从“理解文本”到“感知世界”

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?