中国大模型正加速从“跟跑”走向“并跑”,在一些赛道上开始“领跑”。
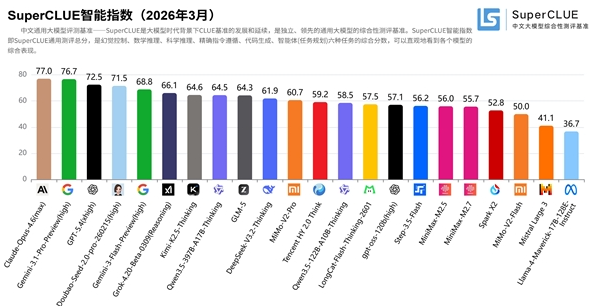
3月30日,中文大模型基准测评SuperCLUE公布了2026年3月最新榜单。本次共有22款海内外主流模型参评,覆盖数学推理、科学推理、代码生成等六大关键任务。结果显示,以“豆包”为代表的国产模型已顺利挺进全球顶尖阵营。

全球视角:海外闭源仍占上风,豆包紧紧跟进
从本次测评的总分榜来看,海外闭源模型依旧展现出深厚实力:
前三强: Anthropic 的Claude-Opus-4.6、Google 的Gemini-3.1-Pro以及 OpenAI 的GPT-5.4位列全球前三。
国产之光: 字节跳动旗下的豆包(Doubao-Seed-2.0-pro)以71.53分夺得国内第一,稳居全球第一梯队,与 GPT-5.4 的差距缩小至0.95分。
智能体突破: 在智能体的任务规划维度,豆包实现反超部分海外模型,跻身全球前五。
小米表现:MiMo-V2 系列数学推理能力突出
作为手机厂商跨界 AI 的代表,小米集团的 MiMo 系列在本次评测中表现稳定:
数学尖子生: MiMo-V2-Pro以60.67分位列闭源模型前列,在数学推理任务中拿下84.03分的高分。
双模上榜: 除 Pro 版本外,开源版本的MiMo-V2-Flash也同步上榜,在代码生成等细分场景中展现出良好的进化潜力。
开源赛道:国产模型实现“包揽式”领先
相较闭源领域的鏖战,国产模型在开源赛道展现出统治级优势:
包揽前三: Kimi-K2.5-Thinking与Qwen3.5-397B等国产开源模型包揽开源榜单前三。
降维打击: 测评数据显示,国产开源模型在整体表现上已显著领先海外同类开源产品,成为全球开发者的新宠。
结语:从“参数比拼”迈向“能力实战”
从这份2026年3月榜单可以看到,中文大模型不再只满足于中文语境理解,而是在逻辑推理、代码生成等硬核领域与全球顶级模型正面较量。随着豆包持续上位,以及小米 MiMo在细分能力上的深耕,国产大模型正迎来真正的“实战爆发期”。




















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?