

3月26日消息,谷歌研究(Google Research)正式推出全新向量量化压缩方案TurboQuant。借助创新的 PolarQuant 与 QJL 技术,它能够将大语言模型(LLM)推理阶段的KV Cache(键值缓存)内存占用至少缩小6倍,并在 Nvidia H100 GPU 上把注意力计算速度提升最高8倍;在多项长上下文基准中实现零精度损失。这一进展有望显著降低AI部署成本,加速长上下文应用落地。
KV Cache 痛点:高维向量内存开销惊人
当 LLM 处理长序列时,需要维护由键(Key)和值(Value)组成的缓存,用于快速执行注意力计算,避免重复开销。然而,随着上下文变长,KV Cache 的内存需求会快速膨胀,成为限制推理效率与部署规模的关键瓶颈。

传统向量量化虽能压缩数据,但往往需要额外保存量化用到的常数(如缩放因子、零点等),这些通常以高精度存储,每个值还会引入1-2bit额外开销,部分抵消了压缩收益。
TurboQuant 核心创新:PolarQuant + QJL 双阶段压缩
TurboQuant 采用两阶段、无需训练的压缩框架,巧妙规避了传统量化的冗余成本:
PolarQuant(极坐标角度压缩):
先对向量做随机旋转,再将笛卡尔坐标(X/Y/Z 等)转为极坐标(角度 + 半径)。由于角度天然落在可预测的固定范围内,可不再为边界归一化保存额外常数,从而实现更高效的压缩。
QJL(1-bit 纠错,Quantized Johnson-Lindenstrauss):
在 PolarQuant 之后仍会有残余误差。QJL 通过 Johnson-Lindenstrauss 变换进行降维,并以仅1bit(+1/-1 符号)量化。借助特殊的无偏估计器,在计算注意力分数时即可完成误差修正,无需额外内存开销,确保整体估计无偏。
两者协同后,TurboQuant 能将 KV Cache 压缩到约 3-bit 水平,同时保持内积估计无偏且精度稳定。
基准测试表现:全面领先,天然适配长上下文
谷歌团队在 Gemma、Mistral 等开源模型上进行了广泛测试:
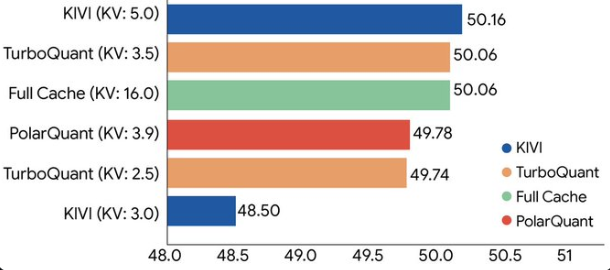
- LongBench(涵盖长文本问答、代码生成、摘要等):TurboQuant 与现有 KIVI 等基线持平或更优,整体表现领先。
- Needle In A Haystack等检索类任务:下游得分保持完美,同时 KV 内存压缩至少 6 倍。
- Nvidia H100 实测:在 4-bit 配置下,注意力 logits 计算速度提升最高8倍。
此外,在 GloVe 等向量数据集上,TurboQuant 的召回表现也优于 PQ、RabbiQ 等传统方法。
编辑点评:TurboQuant 无需对模型做重训或微调,可直接接入现有 LLM,适用于所有依赖向量量化的场景,包括数据库检索、推荐系统与向量搜索。这不仅能让消费级单卡承载更长上下文(如数十万 token),也显著降低企业级 AI 服务的硬件门槛。
行业意义:AI 推理效率新标杆
随着长上下文与多模态应用兴起,KV Cache 内存已成为 AI 基础设施的核心限制因素。TurboQuant 的“近最优、数据无关”量化框架,为高效推理提供了新范式。谷歌研究表示,相关技术细节已在 ICLR2026 等会议论文中阐述,后续代码与实现将逐步开源。
未来,TurboQuant 有望被集成到 vLLM、TensorRT 等主流推理框架中,进一步推动 AI 部署的普及与规模化。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?