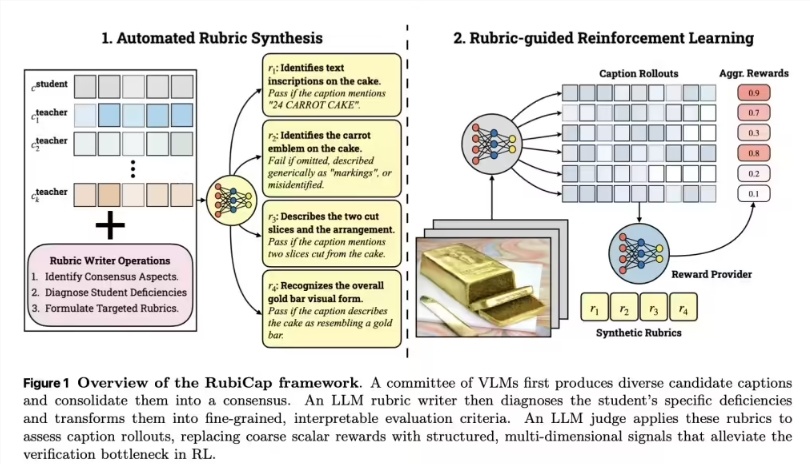


在计算机视觉圈,一直存在一个难点:如何让 AI 像人类一样看图,并把画面里的每个细节讲清楚。近日,苹果公司联合威斯康星大学麦迪逊分校,正式发布了一款名为
这套框架面向“密集图像描述”,目标是不再只给出笼统概括,而是能精准捕捉并说明“桌上的红苹果”或“远处的行人”等细节。

小模型反击的强化学习:Qwen2.5 充当“裁判”
传统图像标注不是成本高的人工作业,就是依赖容易产生幻觉的大模型,导致数据质量参差不齐。苹果研究团队用一套创新的强化学习方案来破题:系统先用 GPT-5 和 Gemini 2.5 Pro 生成候选描述,随后由 Gemini 2.5 Pro 提炼评分标准,再由 Qwen2.5 模型 担任裁判打分反馈。
这种结构化且精准的反馈,让模型在训练过程中能清楚发现并修正错误,从而在更小的参数规模下也能获得更高的描述准确度。
小而强的胜利:更低幻觉率超越超大规模模型
基于该框架训练出的
这一结果清楚地表明,高质量的图像理解并不依赖一味堆砌参数,更关键的是更科学的训练范式。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?