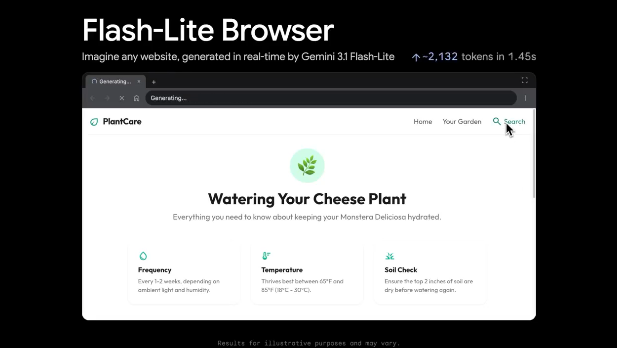


Google DeepMind 今日发布了其在生成式 AI 速度上的一次突破:Gemini3.1Flash-Lite。该模型依托超高的推理效率,几乎可以“实时”渲染网页,把 AI 从简单文本交互推进到动态 UI 的前沿。
性能飞跃与成本权衡
按照官方信息,Gemini3.1Flash-Lite 的首响应速度相比前代 Gemini2.5Flash 提升了 2.5倍。其吞吐量同样亮眼,每秒可产出超过 360个 Token。在第三方机构 Artificial Analysis 的多模态测试中,这款轻量模型的表现甚至超过了如 Claude Opus4.6 等体量更大的对手。

不过,速度提升也伴随价格变化。当前该模型的输出费用已从每百万 Token0.40美元提高到 1.50美元,反映了低延迟高性能背后的算力溢价。

“伪浏览器”演示与应用场景
谷歌同步推出了一个基于该模型的“伪浏览器”演示应用。用户只需输入描述性指令,系统即可在毫秒级直接生成并渲染对应网页内容。尽管在处理复杂逻辑时仍有不稳定之处(内容可能随时间变得混乱),但它在以下场景展现出不小的潜力:
-
快速原型设计: 即时把 UI 概念和创意可视化。
-
动态交互界面: 可依据用户实时意图调整网页结构。
-
低延迟多模态任务: 在需要极速反馈的场景中替代重型模型。
目前,Gemini3.1Flash-Lite 已正式上线 Google AI Studio 及 Vertex AI 平台,欢迎前往体验这份“极速生成”的魅力。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?